
Figure 1:Our understanding of vision as relating to the optics of the eyes and subsequent information integration in the brain goes back hundreds of years.[1]

Figure 1:Our understanding of vision as relating to the optics of the eyes and subsequent information integration in the brain goes back hundreds of years.[1]
Our exploration of the science of perception will cover all of our senses. However, we will spend most effort to study vision. There are several reasons for this choice:
1. Most of our sensory brain areas are concerned with vision.
2. Vision seems to be more "dominant" than other senses.
3. Even dreams seem to be mostly visual.
4. Vision is relatively easy to study experimentally.
5. Accordingly, vision is the most studied sense. We will always follow the same outline for the senses that we will discuss:
First, we will discuss the stimuli that these senses detect. This implies that we will start with physics and chemistry. Some of that physics will also require us to review certain mathematical principles and laws.
Next, we will explore the psychology of each sense. That is, we will briefly go over what is known from behavioral measurements about how we sense and perceive each sense in isolation or in combination with the other senses.
Then, we will review the anatomy of our sense organs, including their neuroanatomy. This includes a brief review of the basics of systems neuroscience as well.
Lastly, we will survey what is known about the brain mechanisms that go along with the sensation and perception of each sense.
You might be most interested in the last of these steps only. That would be understandable. After all, we started with some puzzling philosophical questions surrounding perception, and you might hope that we will (only) find an answer to these questions once we learn what the brain does when we perceive something.
However, as you will see, we will not find satisfying answers to these philosophical question at that point. In fact, the mystery might deepen. You will also find that starting from physics becomes important and informative at that point.
This is not meant to let you down. In fact, there are suggestions for satisfying answers, and we will discuss them at the end. These proposals will only be comprehensible, though, after we completed the full survey of the physics, anatomy, psychology, and neuroscience of the senses.
You might have noticed that all chapters in this book are sorted by what we commonly define our main senses. And all of them will be organized as this one:
We will first discuss the physics or chemistry that underlies the sensory stimuli that are associated with each sense.
Then we will discuss what has been studied about the perception that each of these senses evoke using behavioral techniques, including psychophysics and verbal report.
Only then will we discuss what is known about the neural mechanisms (neuroanatomy and neuronal responses) that are associated with each sense.
This might seem like an unusual organization for a textbook on sensation and perception. More commonly, these three separate fields of study (physics/chemistry, neuroscience, and perceptual psychology) are presented as intertwined. Indeed, there are many benefits of presenting some psychophysical phenomena in the context of the physics of stimuli or neuronal connections and responses. We thus will allow for a bit of flexibility and do so occasionally as well.
However, the overall goal here is to retain a certain consistent logical structure to our approach. And, in doing so, to repeatedly appreciate the difference between the physics/chemistry of sensory stimuli on the one hand and our perception of the related sensory activations on the other hand.
So, let us begin.
PHYSICS¶

Figure 3:Visual sensation starts with light rays entering our eyes, bending at the lens and ending up as a two-dimensional projection (image) at the back of our eyeballs - the retina. As a consequence, visual sensation is subjected to the laws of optics - the geometry of light propagation.[2]

Figure 3:Visual sensation starts with light rays entering our eyes, bending at the lens and ending up as a two-dimensional projection (image) at the back of our eyeballs - the retina. As a consequence, visual sensation is subjected to the laws of optics - the geometry of light propagation.[2]
So, when we think of seeing (vision), we usually start with a process that starts with light (if we put dreams and hallucinations aside for a moment).
But what is that - light?
Light¶
The physics of light (optics) is a rabbit hole that is easy to fall down in. One reason for that is that it can quickly lead us from high school physics to quantum physics and relativity. Luckily, we do not have to do that for garnering a basic understanding of physics relevant for our visual perception.
In simple terms, light is electromagnetic radiation.
Light, in fact, is just the part of the electromagnetic spectrum that we can see (due to the biophysics of our photoreceptors).

Figure 5:A rainbow shows the spectrum of natural (sun)light.[3]
But what do we mean by “radiation” or, more specifically, “light rays”?
In simple terms, we mean “waves”. In other words, rather than little particles (small “balls” of light), we usually refer to something rippling in a wave-like fashion whenever we speak of radiation.
And this is good news. Because waves are somewhat simple when it comes to their mathematics.
The simplest type of wave, mathematically speaking, is a sine wave.
Somewhat confusingly, a sine wave refers to an (infinite) amount of waves that periodically “go up and down”. When we refer to just one out of this (infinite) series of individual waves that collectively make up a sine wave, we call that singular “up-and-down” wave a cycle. In other words, a single cycle is what you are left with if you “cut out” a snippet that starts either at a peak and ends at a peak (peak-to-peak), or starts at a trough and ends at a trough (trough-to-trough) - or, indeed, any other reoccurring point of a sine wave.
Why the mathematics of sine waves seems so simple if that it can be thought to boil down to just 3 numbers, or more precisely, numeric values for most of its applications.
Even better, one of these numbers (or more precisely, numeric values) often can be ignored. This means that for much of what we need to discuss regarding light waves, two values (numbers) will be sufficient.
Loosely speaking, the first of these two numbers answers:
how small or tall is the (sine) wave?This peak-to-trough distance is called the amplitude (sometimes also referred to as magnitude).
And the second number answers:
how rapidly or slowly changing is the (sine) wave?In other words this number describes the peak-to-peak or trough-to-trough distance. When drawn out on a piece of paper, this distance determines the length of a single wave. Intuitively, this number is called the wavelength.
The inverse of wavelength is called frequency, and the two notions are often used interchangeably. Of course, due to their inverse relationship, the higher the frequency, the lower the wavelength (and vice versa).
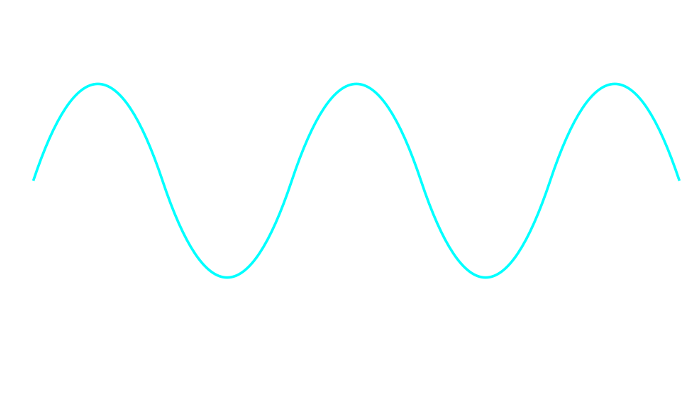
Figure 6:Sine waves are well described by two numerical values: their wavelength and their amplitude.[4]
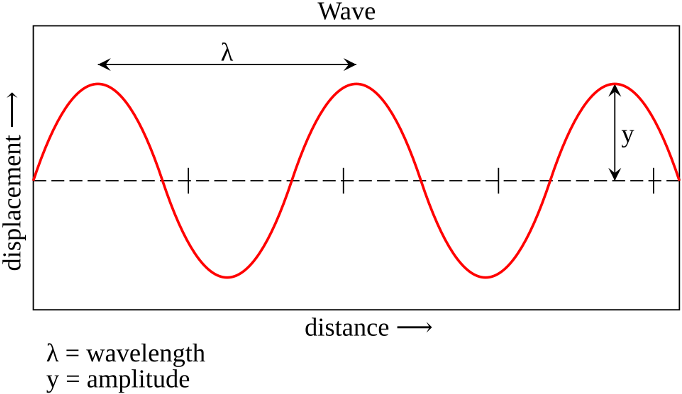
Figure 6:Sine waves are well described by two numerical values: their wavelength and their amplitude.[4]
The third number needed to fully describe a sine wave is phase - how much its peaks and troughs are “shifted” relative to other sine wave of the same wavelength/frequency and amplitude.
Now, thinking of light as sine waves with varying wavelength (or frequency) is not the entire story.
We will also (necessarily) refer to light as if it is made of individual particles called photons. Photons are small “balls” of light (corpuscles). This means that we can count how much light meets our eye by counting individual photons, for example.
The problem is that sine waves are continuous, and not made up of individual (discrete) particles. This means that light has to be either one or the other - a wave or a bunch of particles. So, why will we talk about light as if it were one or the other at different times?
The answer is surprising: Modern physics tells us that it seems as if light really is either a wave or a particle at different times - it can change from being one to being the other.
This is called the wave-particle duality of light. In the following, we will touch on this topic briefly. A full grasp on this confusing phenomenon arguably can only be obtained via a mathematical formalism that goes beyond the scope of this book. Instead, our goal is merely to understand why physicists would accept such a strange notion before we move on with the realization that it is acceptable to discuss the physics of light using the “picture” of particles (photons) sometimes and the “picture” of waves, or light rays, on other occasions.
Wave-Particle Duality¶
The classic demonstration of wave acting like a wave or like a particle, depending on context is the double-slit experiment. It is super simple. All that is done is to shine light through two neighboring slits at the same time.
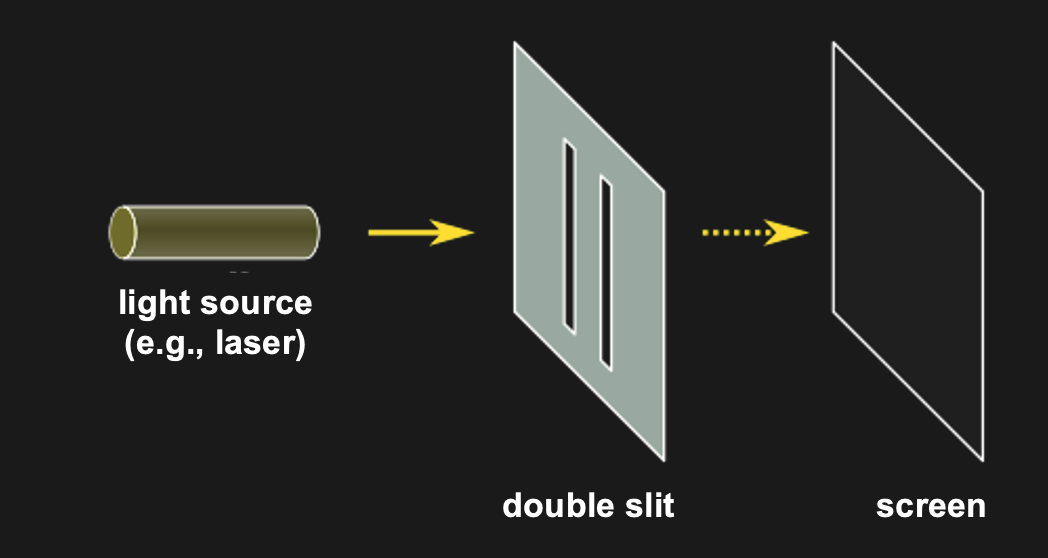
Figure 10:The double slit experiment consists simply of shining light on a surface with two slits in it. All light except for that passing through the slit gets blocked. The question is what one sees on the other side of the double slit (e.g., on a wall or screen that is placed behind the double slit).[6]
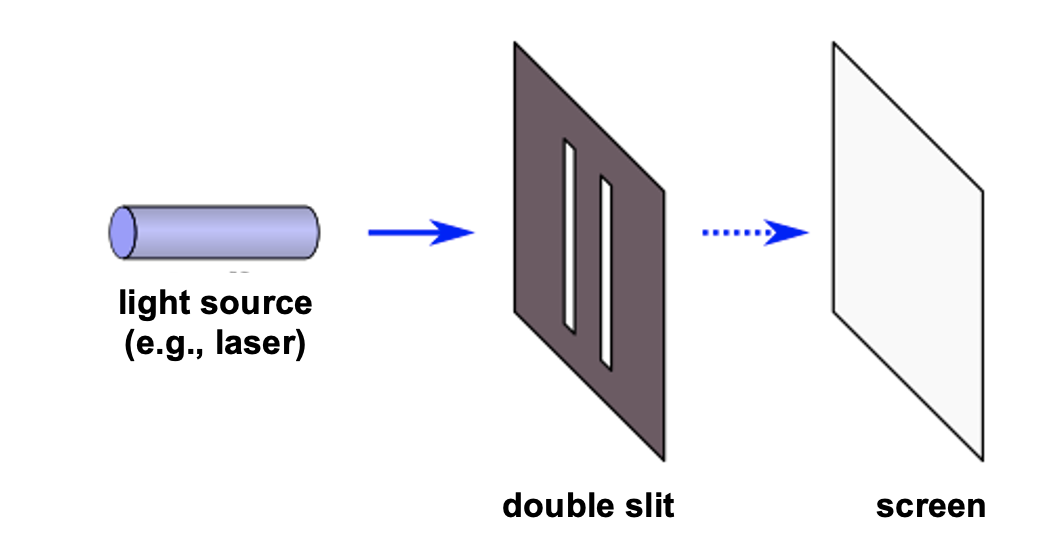
Figure 10:The double slit experiment consists simply of shining light on a surface with two slits in it. All light except for that passing through the slit gets blocked. The question is what one sees on the other side of the double slit (e.g., on a wall or screen that is placed behind the double slit).[6]
This is not that interesting it seems. Except for the following: Imagine what should happen if light were made of a stream of ball-like particles (photons).
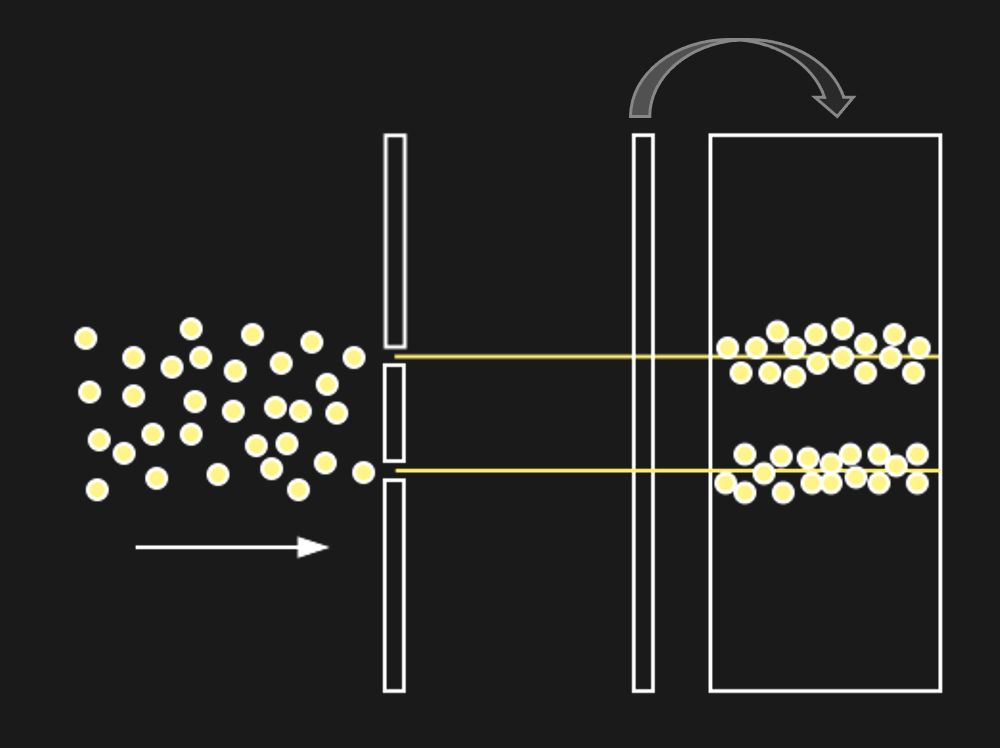
Figure 12:If light were made of particles (photons), we might expect to see the above.[7]
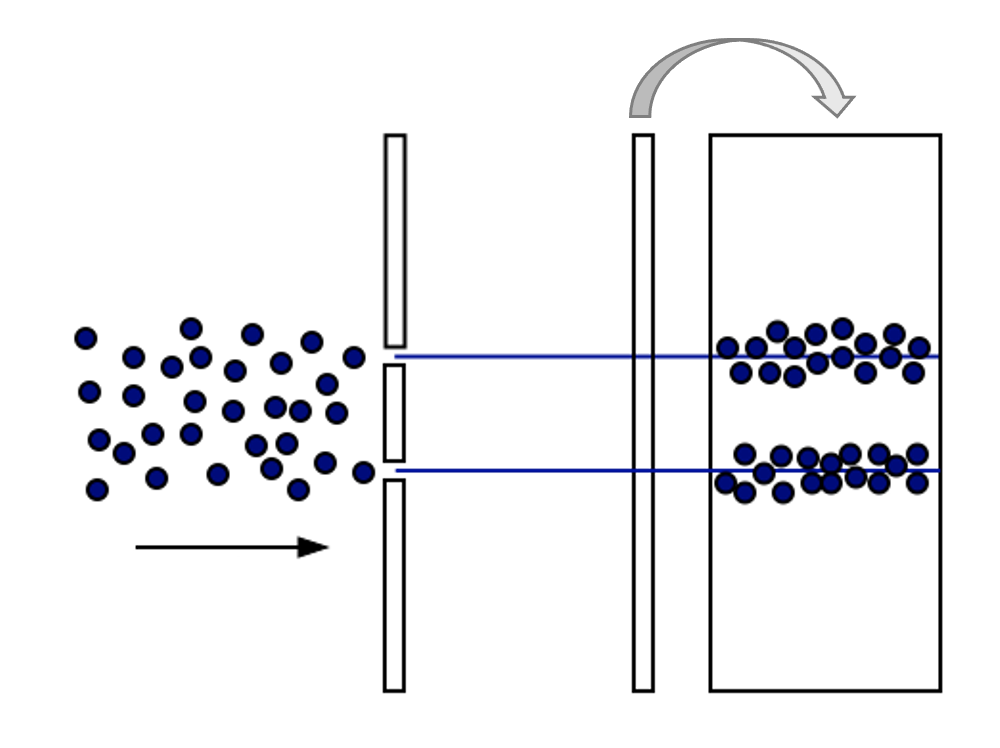
Figure 12:If light were made of particles (photons), we might expect to see the above.[7]
But if light were a wave, we would expect to see something very differently behind the slits. The reason for that is how waves behave when they go through slits:
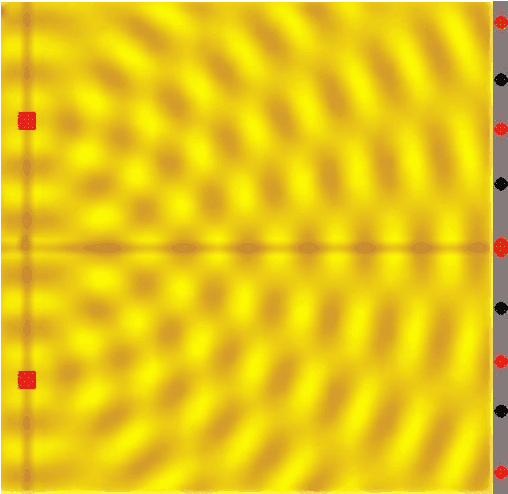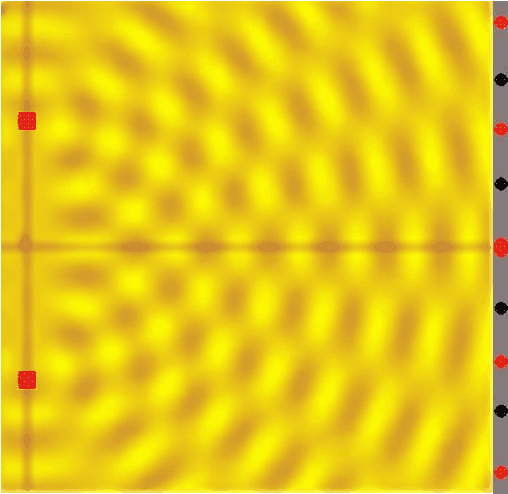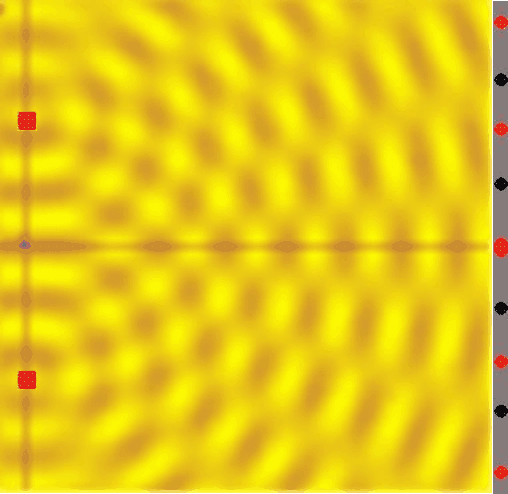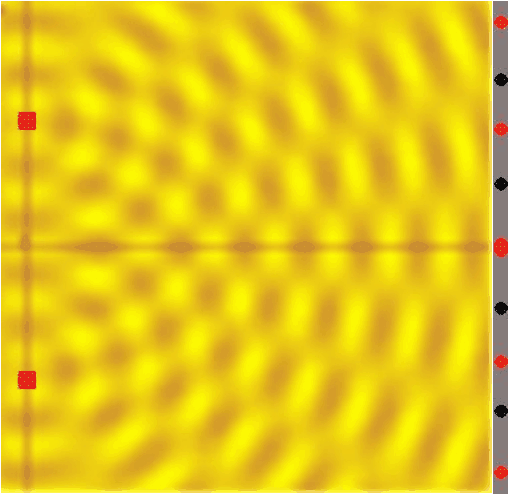
Figure 14:If a single wave front goes through two slits, the result is that it splits in half. In other words, two new wave fronts start to extend from the slits, one on each side. These waves interact (_interfere) with each other as they radiate out. The computer simulation shows how two such waves lead to such a complex pattern of interference.[8]
The complex pattern of a single wave front splitting into two when passing two slits, and the two split-off waves interfering with each other means that we should expect a “wavy” pattern behind the double slit - very different from the two “piles” of particles we expect for photons.
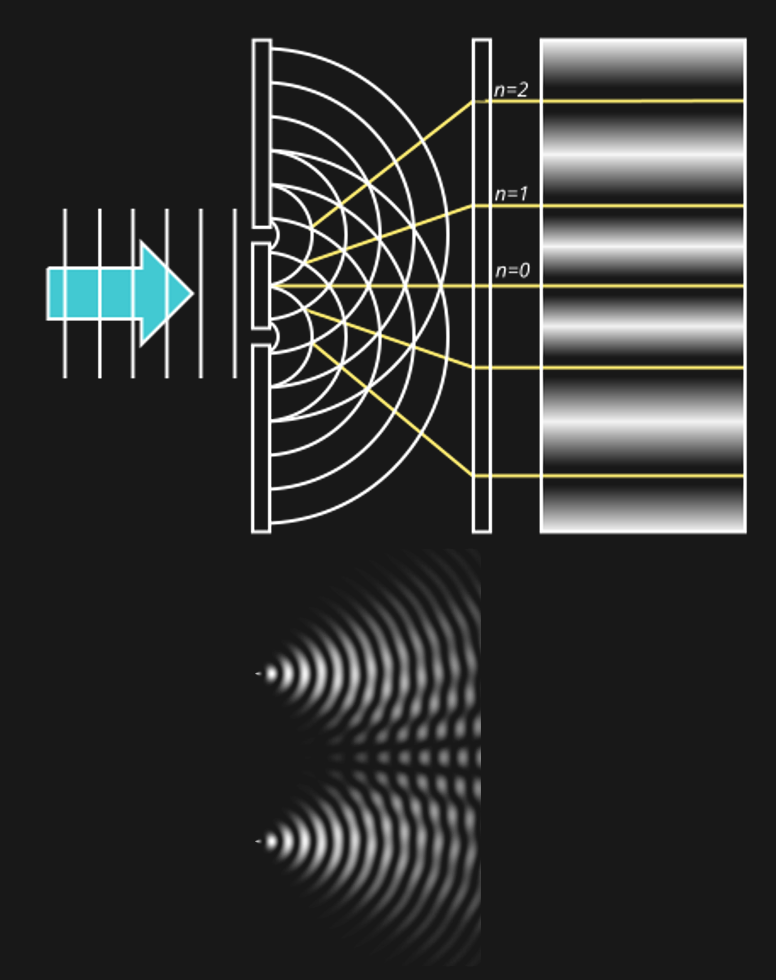
Figure 14:If light were a wave, we might expect to see the above.[9]
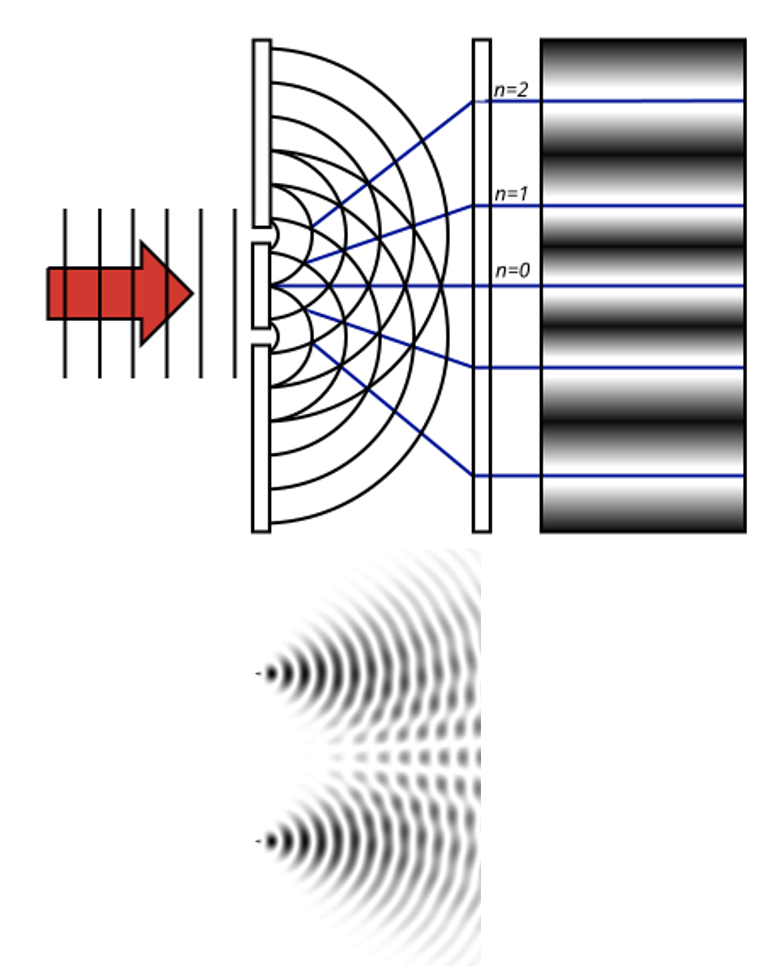
Figure 14:If light were a wave, we might expect to see the above.[9]
Now, what we find is... either one of the two. Depending on the circumstances.
If the experiment is performed as described above, the result looks like light is a wave.
But if the experiment is augmented by adding some kind of measurement device that measures whether a light particle went through one or the other slit. This might sound like it makes no sense. Why measure particles of light, if the pattern suggests that light is a wave?
Well, the fascinating result is that if we treat light like it is made of particles, it behaves like it is made of particles.
In other words, when we alter the experiment to measure single photons and which slit they went through, the resulting pattern behind the slit looks like two dots, or “piles” of particles. If we turn off the measuring device, the pattern changes and looks wavy again.
Physicists are as puzzled about this observation as you might be. There are a lot of debates about how to make sense of this interesting phenomenon. But for us, it might suffice to note that there is no clear answer to whether light consists of continuous waves (light rays) or discrete particles (photons). More than that, light sometimes seems to act as if it were on or the other.
Needless to say, we are just scratching the surface here. Light is at the center of all modern physics: The duality of light waves and light particles (photons) is a central conundrum of quantum physics. At the same time, the assumption that the speed of light expansion is fixed inside a vacuum is central to Einstein’s relativity. These are all deeply fascinating (and sometimes highly technical) topics that fill up entire textbooks on their own. Luckily, almost none of that is relevant for human sight.
Spectra¶
As we discussed above, light waves are best described as sine waves. This is good news. Sine waves are easy. We already established that any sine wave is described by only three numbers:
Frequency, or Wavelength (horizontal “peak-to-peak” in plots)
Amplitude, or Magnitude (vertical “peak-to-peak” in plots)
Phase (relative shift in plots)
To make things even better, we can often ignore phase when it comes to sine waves in the science of perception, thus leaving us with just two numbers to describe a rather complex phenomenon, such as a light wave.
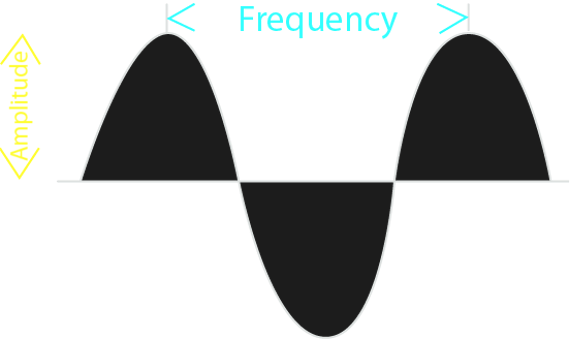
Figure 17:Amplitude and frequency are just two numeric values that tell us almost everything there is to know about sine waves.[10]
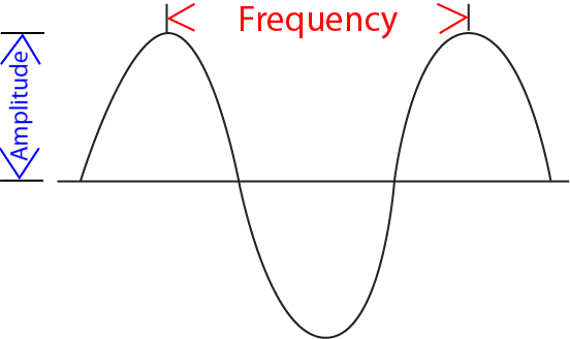
Figure 17:Amplitude and frequency are just two numeric values that tell us almost everything there is to know about sine waves.[10]
So, just two numbers can well describe something as complex as a (light) wave. This property makes it very attractive for us to discuss the physics of light by treating it as light waves or light rays (though we will also treat it as particles, or photons, on other occasions).
Now, in practice, light consists of more than just one sine wave. In fact, light usually consists of a very large number of combined sine waves.
Here, too, there is good news.
Mathematically, it is relatively easy to take something (a signal, or time series) consisting of many sine waves, and find out exactly what sine waves it is made out of. More than that, we can find out for such a signal (such as light) consisting of a sine wave mixture, which frequencies of sine waves this mix is made out of as well as the amplitude (and phase) of each of these frequencies. The result is what we call a spectrum: a representation of the data as amplitude (or phase) as a function of frequency.
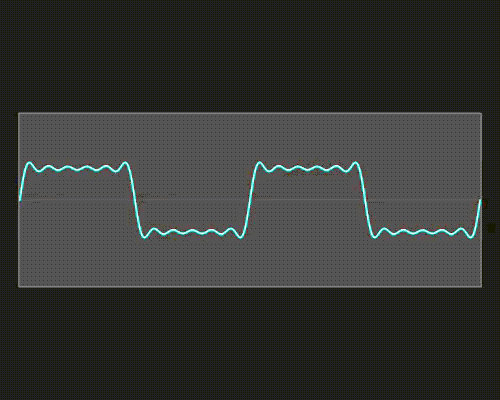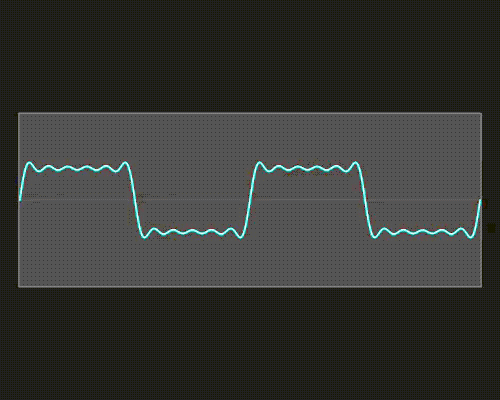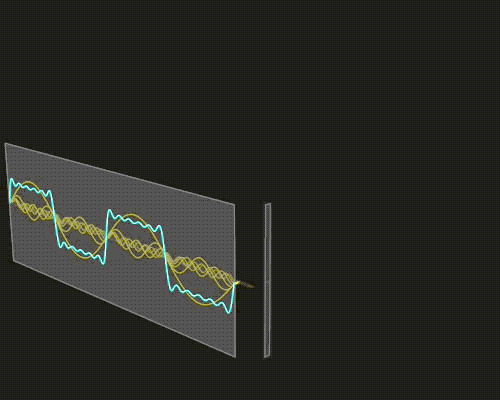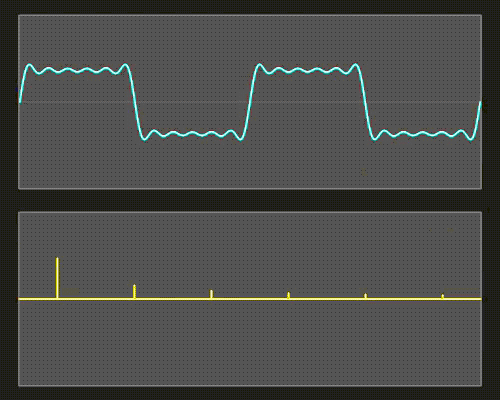
Figure 19:The Fourier transform is a mathematical procedure that decomposes a mix of sine waves into a list of component sine waves of varying frequency and amplitude. The result is an amplitude spectrum. The Fourier transform also provides a spectrum that lists the phase for each of these component sine waves, but we can ignore this for now.[11]
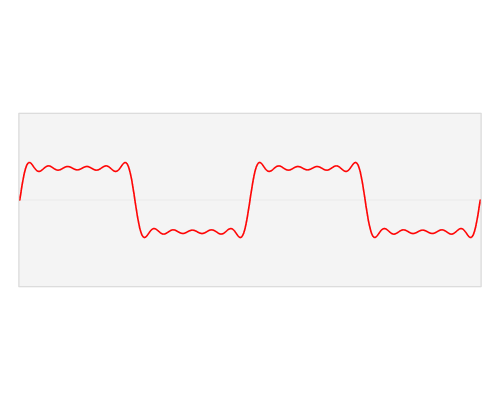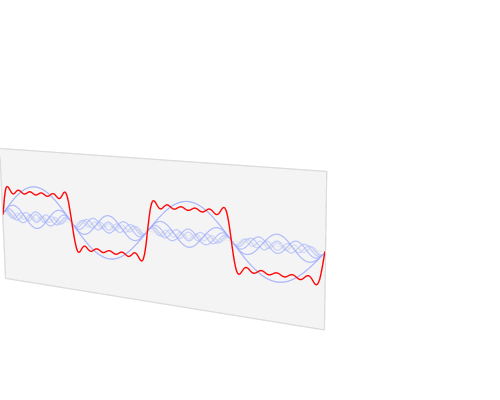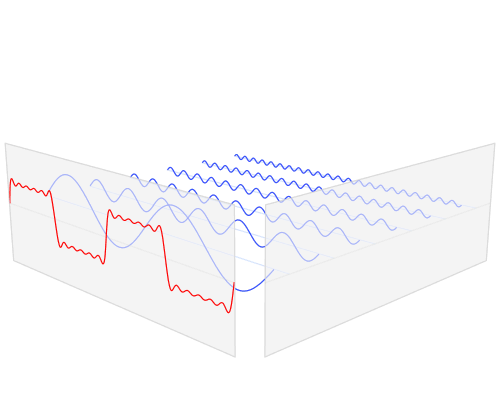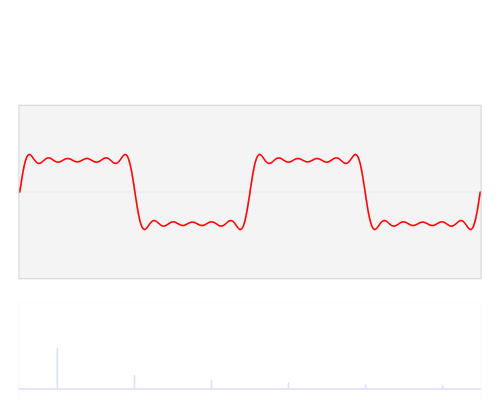
Figure 19:The Fourier transform is a mathematical procedure that decomposes a mix of sine waves into a list of component sine waves of varying frequency and amplitude. The result is an amplitude spectrum. The Fourier transform also provides a spectrum that lists the phase for each of these component sine waves, but we can ignore this for now.[11]
The mathematical process that achieves this is called a Fourier Transform, and the underlying mathematics is beyond our scope. But it is important to note that this transform is reversible: we can apply it to component sine waves and obtain the combined mixed (complex) signal. Or, we can start from the complex (combined) signal consisting of a mix of sine waves and find out all of its components.
You can think of an amplitude spectrum returned by a Fourier transform as a cookie recipe: It tells you what (i.e., which frequency) to add and how much (i.e., amplitude) of each. A phase spectrum also tells us the phase of each frequency, but - as stated above - we can ignore that most of the time.
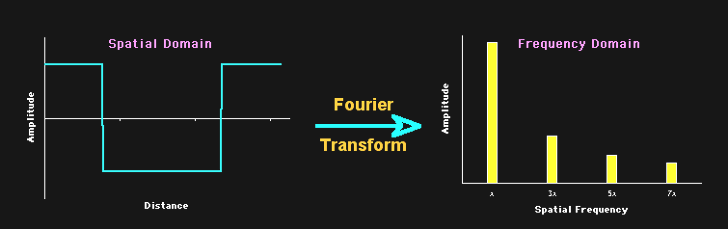
Figure 21:A spectrum tells us which frequencies and their amplitudes collectively make up a mixed signal of sine waves.[12]
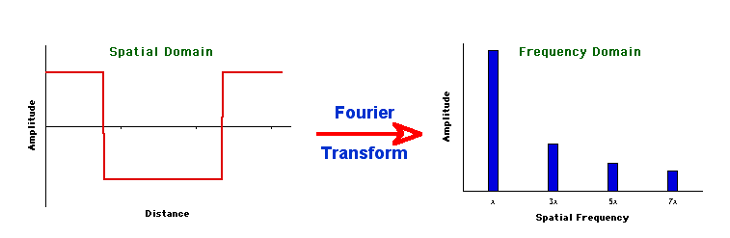
Figure 21:A spectrum tells us which frequencies and their amplitudes collectively make up a mixed signal of sine waves.[12]
Filters¶
A filter lets some components of a mixture pass (while holding back others). We will encounter filters throughout our survey of the science of sensation and perception, but they are easiest to explain in the context of the light spectrum.
There are four different kinds of filters when it comes to frequencies:
Low pass filters: let only low frequencies pass
High pass filters: let only high frequencies pass
Band-pass filters: let neither low frequencies nor high frequencies pass
Notch filters: let only low and high frequencies pass
Given what we just discussed regarding sine waves and spectra, we can make sense of these four filter types by examining what they do to a wave that consists of three sine wave components of the same amplitude: a low frequency sine wave that is added to a mid-frequency sine wave, and a high frequency sine wave. When a Fourier transform is applied to this complex wave that consists of the sum of these three component sine waves, it returns a spectrum that shows each of these three component sine waves.
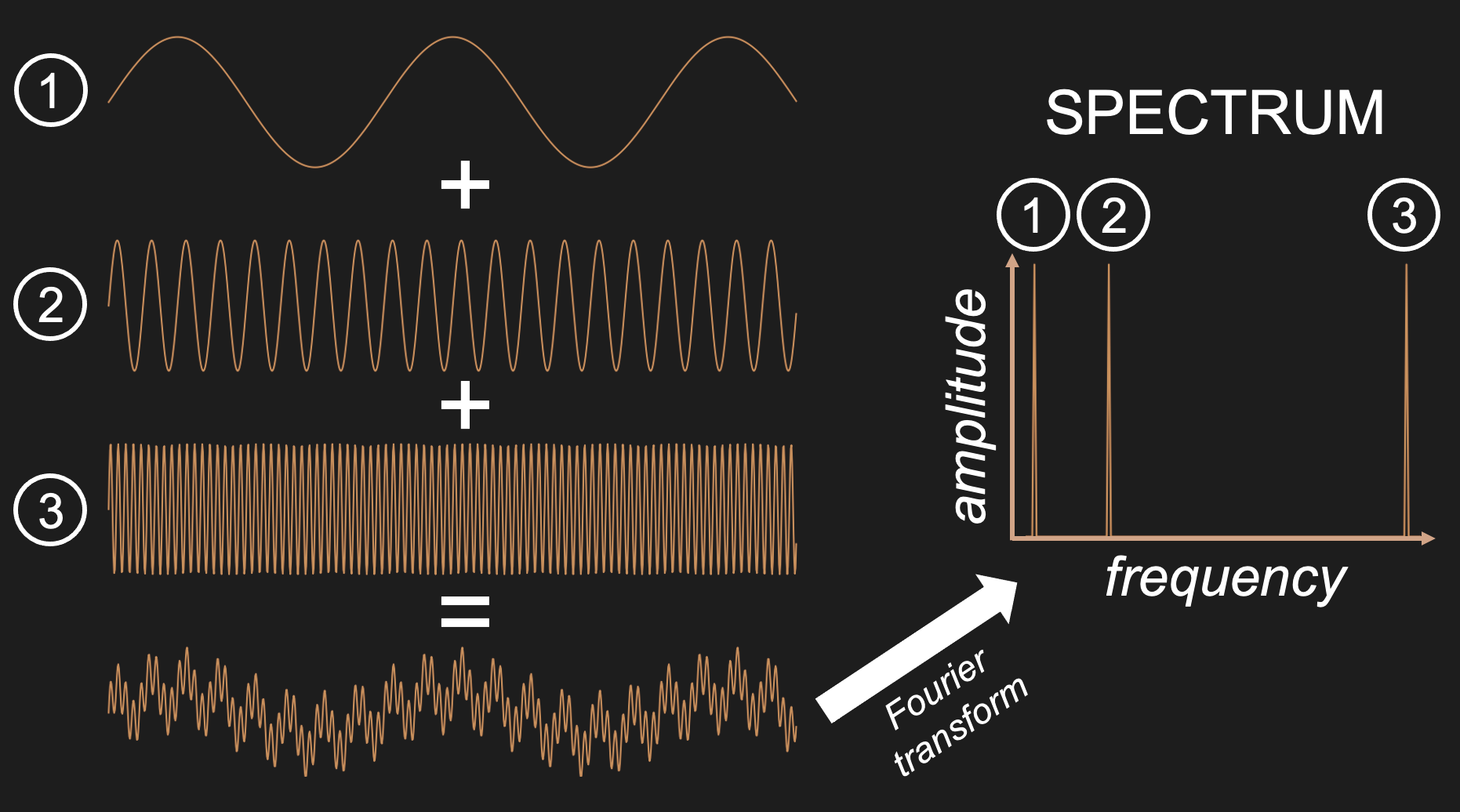
Figure 23:Adding three sine waves of equal amplitude but varying frequency produces a complex wave.
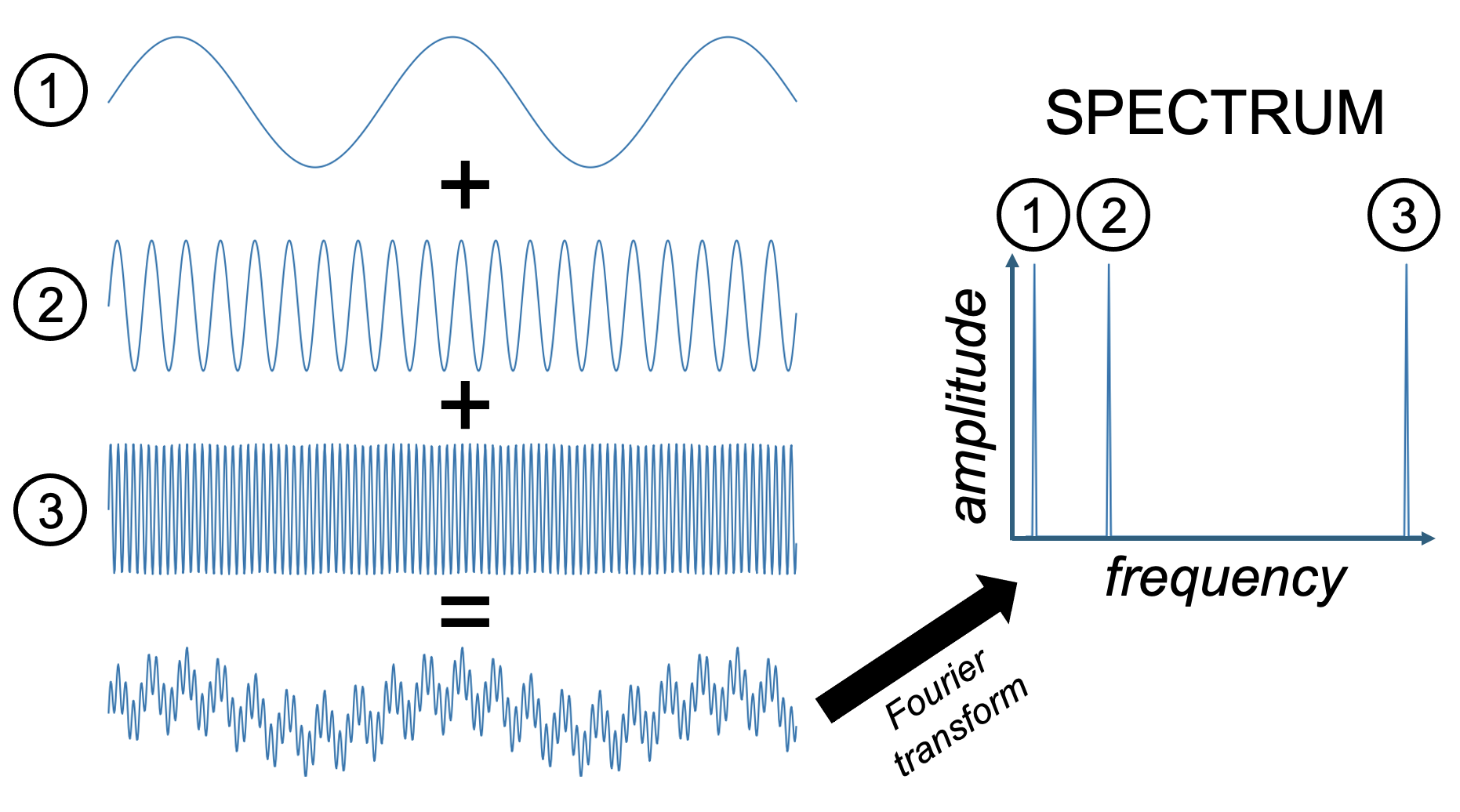
Figure 23:Adding three sine waves of equal amplitude but varying frequency produces a complex wave.
We can use this summed wave to apply each of the three filter types on it, and observe their outcome.
A low pass filter lets only the low frequencies pass. In our case, this returns the lowest frequency component sine wave of the summed signal. One way to think about what this means in practice is that low pass filters smooth their input since it lets only pass what changes slowly and eliminates anything that is abrupt.
A high pass filter does the opposite and eliminates anything that changes slowly. The result in practice often looks more “flat” and “jagged”.
A band-pass filter eliminates all low frequency (slow) and high frequency (fast) components. In our case, we obtain the mid-frequency component.
A notch filter does the opposite of a band-pass filter in that it eliminates mid-frequencies. In our case, we end up with a mix of the low and high frequency component sin waves. Since this is still a mix of two sine waves, it looks a bit more complex than a single sine wave. However, because we eliminated one of the three component sine waves, the resulting wave is not quite as complex as what we started out with.
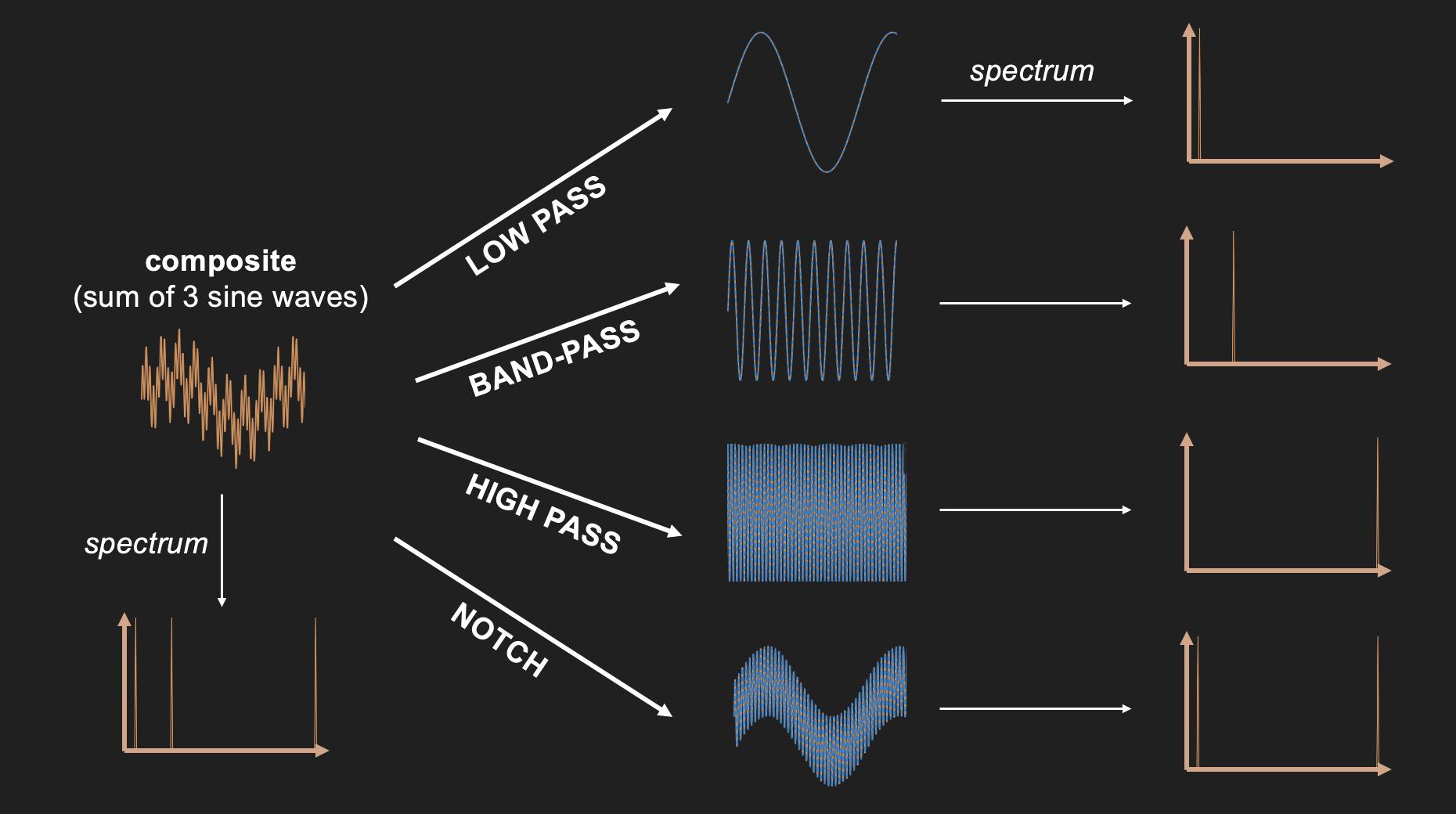
Figure 25:Results of applying each of the four filter types to the sum of three sine waves.
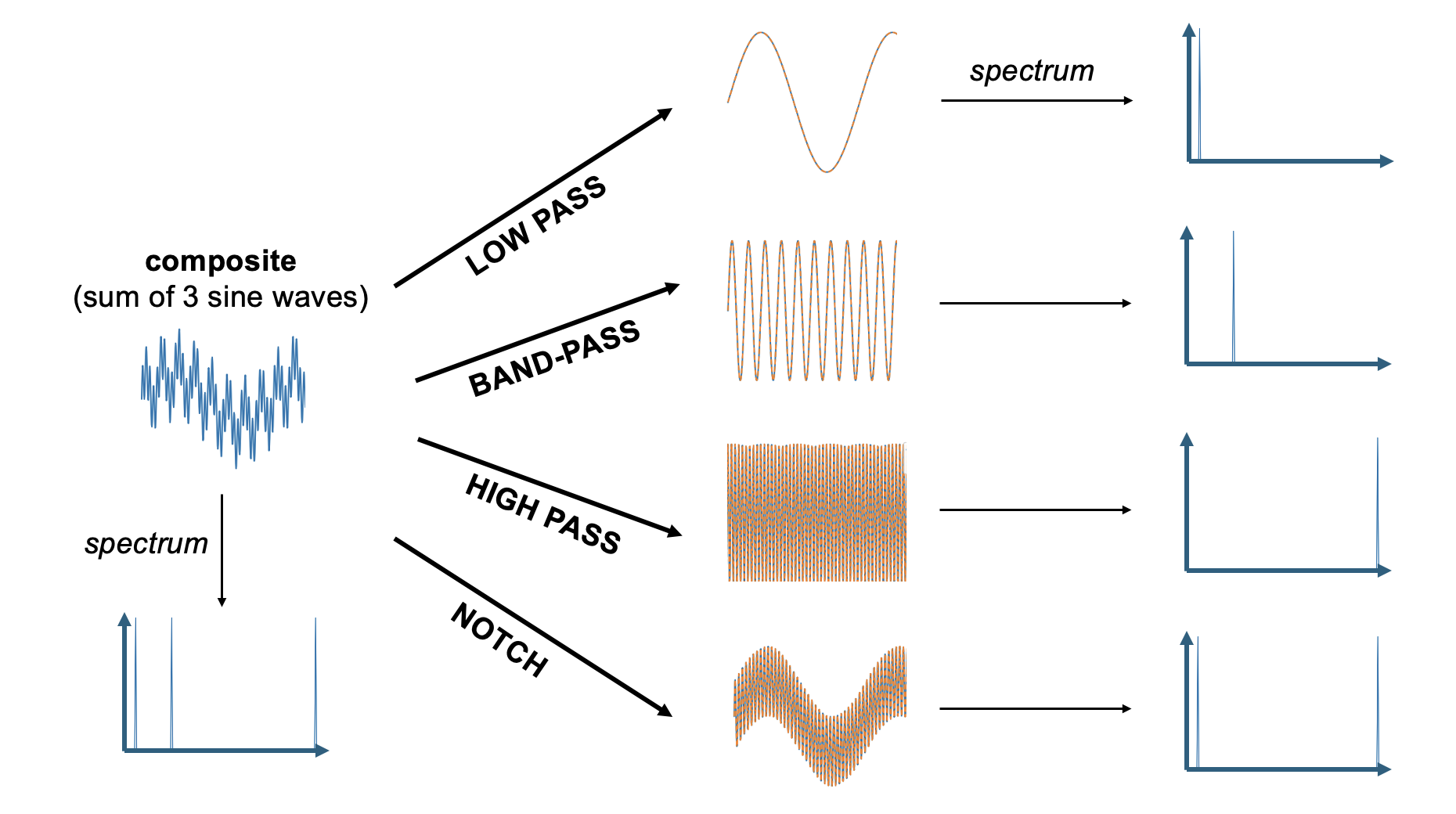
Figure 25:Results of applying each of the four filter types to the sum of three sine waves.
Filters help us to better understand optics. For example, a filter that only lets low light frequencies pass (a low-pass filter for visible light) will look red to us. However, as we will see, the concepts of frequencies, spectra, and filter explain a lot more about visual perception, such as how we see space or details - even faces. In fact, most of our senses can be better understood from a frequency-based perspective.
Optics¶
Before we can discuss the neuroscience of vision, we need to discuss the anatomy of the eye since it functions as an apparatus of sorts that dictates what happens to the neurons. And this apparatus is largely dictated by the function of the lens. And to understand the function of the lens we need to understand the phenomenon of refraction.
To put it glibly, there are only five different things (and mixtures thereof) that can happen to light as it travels through space:
Transmission
Absorption
Reflection
Scattering
Refraction
Let us discuss each of them in sequence.
Transmission¶
Light transmission is exactly what it sounds like: Light travels through something and comes out on the other side exactly as it was before it entered what it travels through. Light just travels along in this case, following the shortest distance.
For example, light does not change as it travels through the vacuum of space. It also does not seem to change much as it travels through air, or a sheet of glass (light does, in fact, change somewhat in these cases, and we will discuss that next, but what dominates is unchanging transmission).
Absorption¶
Some materials do something interesting when they get hit by light - they completely stop its travel. This happens by a process called absorption.
You might remember from high school physics that energy cannot be destroyed in this universe - only be converted from one type to another. In fact, most light as we know it clearly starts by one form of energy being converted into light (as a form of energy): when we burn something and see the light of the fire, when we run electricity through a light bulb, or when we see the sunlight that originates from nuclear fusion on our star - in all these cases light is derived from other forms of energy.
Absorption thus is not “elimination” of light, but conversion as well. Typically, materials that absorb light turn warm - because the light gets converted into heat.
Complete absorption of light results in something being black. On the flip side, completely black objects tend to warm up the most when exposed to a lot of light. This is why black cars turn the hottest compared to cars of other colors when exposed to sunlight.
If only some wavelengths are reflected, the effect is that we see the remaining (non-absorbed) wavelengths. That is, we see color. When this to occurs, we witness a mixture of absorption and another process that allows for the non-absorbed light to travel to our eyes.
For example, water as it enters clear water first is mostly transmitted. In other words, if we are underwater and look around, we can still see what is around us. The reason for that is that a lot of sunlight is transmitted by water - it just enters water and keeps traveling, thus illuminated what is right below the water surface. Yet, going deeper underwater, everything starts looking more blue. The reason for this phenomenon is that all other wavelengths (all larger wavelengths) are slightly absorbed by water, and this absorption slowly adds up as we dive deeper. Eventually, only short wavelength (blue) light remains.
Reflection¶
Reflection is what a mirror does. In this case, light keeps traveling without much change - except a significant change in direction. When light hits a mirroring surface, light “bounces” of that surface in a way that the incoming angle equals the angle with which it bounces off the surface.
Reflection is marked by the production of mirror images exactly because of the process outlined above. What we see when looking at a mirroring surface are light rays that have bounced off from the opposing direction.
There are many materials and surfaces that act like mirrors (i.e., many materials and surfaces cause reflection). What all of them have in common is that their surface is extremely smooth. It is the very fact that the light rays hit a smooth surface of a material that does not allow for transmission or absorption (or reflection) that explains reflection. Why? Because if the surface were not smooth, the result would be scattering - so let us discuss that next.
Scattering¶
Scattering describes light bouncing off a material or object without producing a mirror image. This is what describes any object or material that we can see directly. In order for us to see an object, its surface needs to reflect some light (thus providing reflected light rays that can enter our eyes). Yet, usually this reflected light does not take the shape of a mirror image.
The reason that these (most common) reflections of light are mot mirror-like is that the reflections are disorderly. That is, the incoming angle of light rays leads to various outgoing angles. And the reason for this is that the surface is not smooth. And a non-smooth surface means that the reflected light rays are re-directed in various angles, depending on which part of the surface they hit.
When all wavelengths are scattered, we see a white objects (this is why clouds tend to look white). When we see objects as colored, only some wavelengths are scattered. The remaining wavelengths are absorbed.
Refraction¶
Refraction is what happens inside our lenses. Refraction is akin to transmission in that light travels through the medium that it enters and exits. However, in doing so, it also gets “bent” in that its angle changes systematically, similar to the case of reflection.
An intuitive metaphor for refraction is a marching band of several rows of people walking in lockstep hitting a swamp on one side. The swamp will cause the marchers that enter it first to slow down while the rest of the band keeps marching fast. As the rest of the row of the band, and eventually the following rows enter the swamp, they all slow down respectively. The result is that the entire band takes an angle in direction of marching.
Indeed, refraction is usually explained by the “density” of the material that light travels through. The denser the material, the steeper the resulting angle that light bends as it enters (and exits). This is why mirages happen - hot air is less dense than cold air, and hence light bends differently whenever we have two layers of air of different temperatures on top of each other.
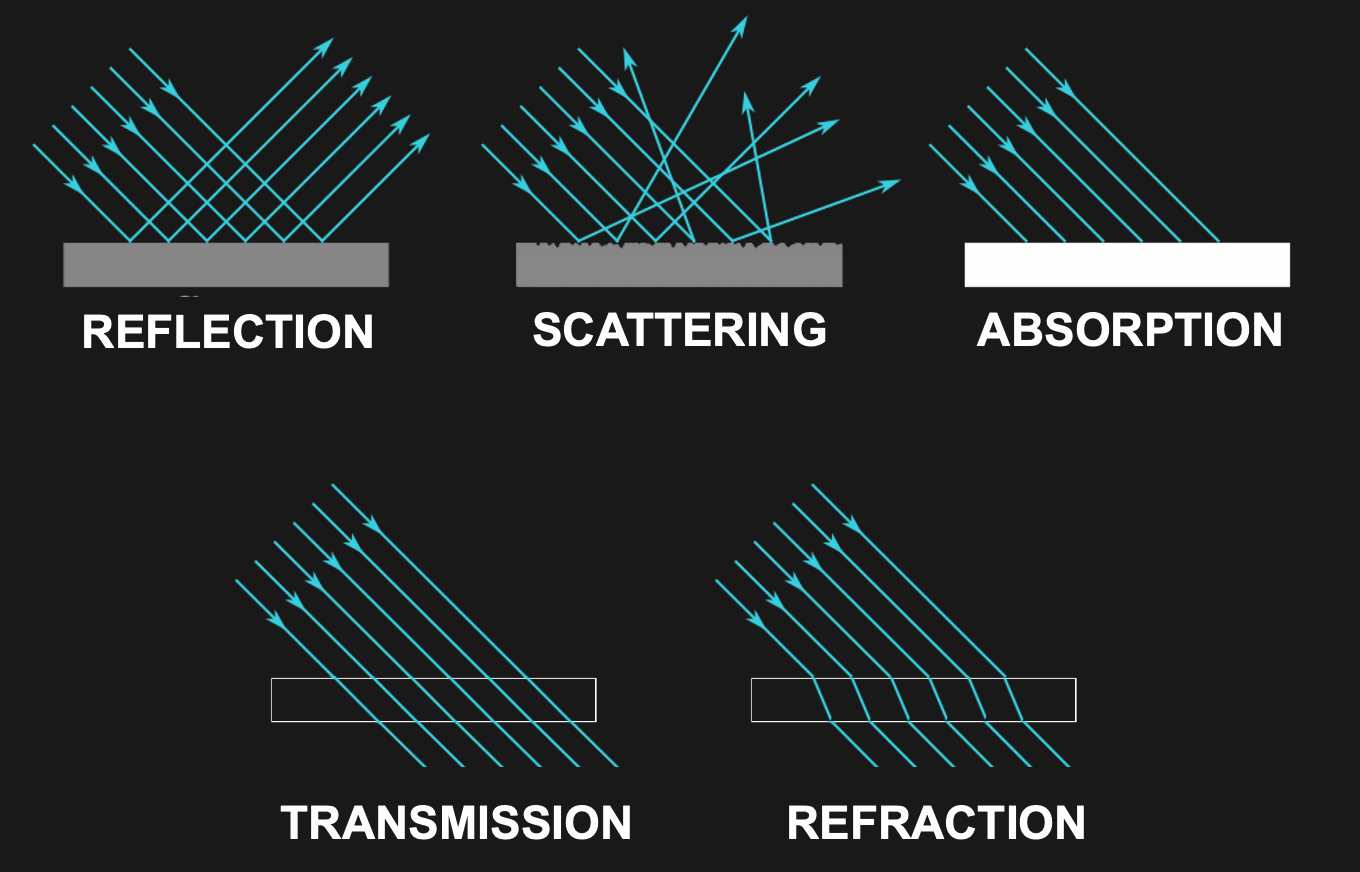
Figure 27:Light can be transmitted, absorbed, reflected, scattered, or reflected.[13]
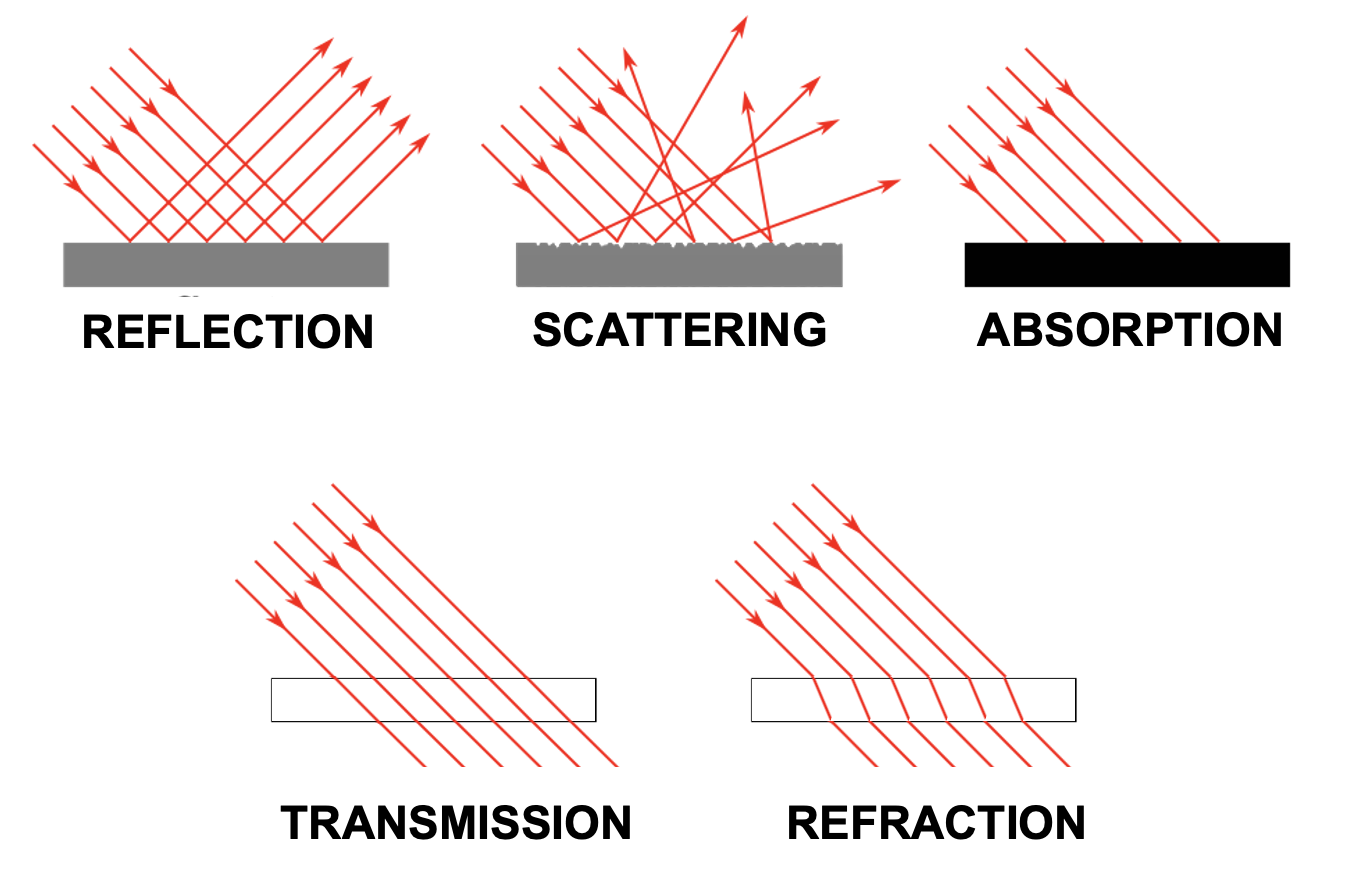
Figure 27:Light can be transmitted, absorbed, reflected, scattered, or reflected.[13]
Focus¶
Now that we earned a solid grasp on basic optics, we can appreciate what happens when light meets our eyes. We will discuss the full anatomy of our eyes as well as the neuronal processes that occur inside our eyes when they are exposed to lights after we discussed what we know about the psychology of vision, but for now let it suffice to examine how our lenses bundle incoming light rays via refraction.
Specifically, our lenses are convergent lenses that, thanks to their material properties and convex shapes, refract light rays in a manner that ensures that what we look at appears in sharp focus. An intuitive way to think about what it means to focus is that any point from which light that is either reflected or scattered ends up as a discrete point on the back of our eye rather than a large area of unsharp blur.
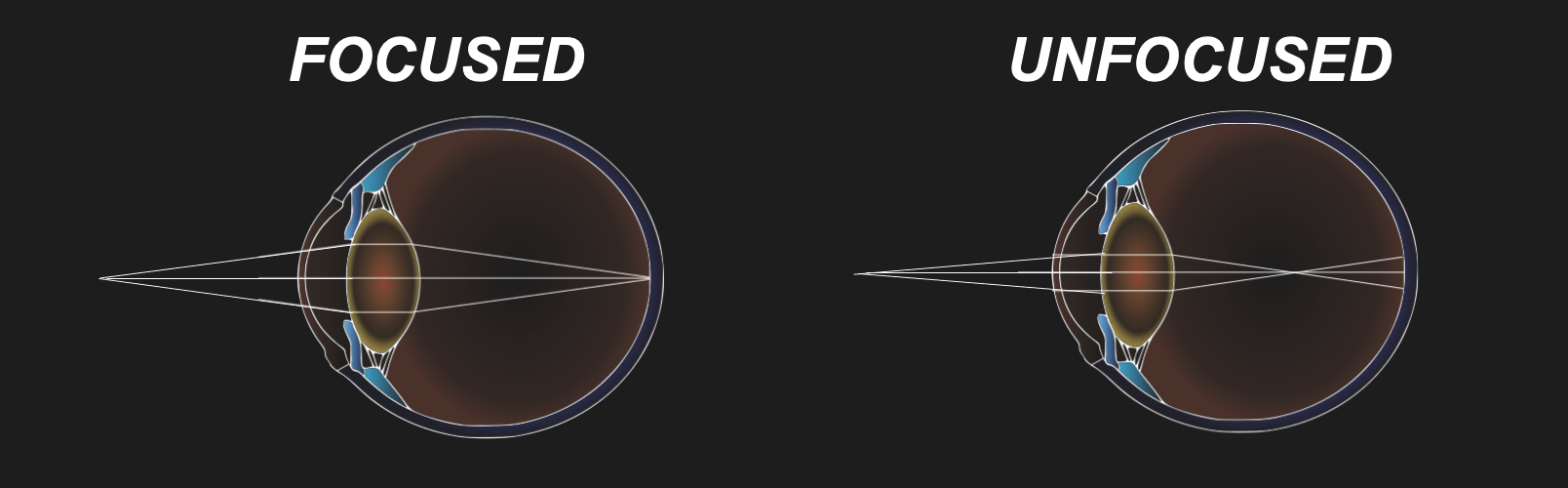
Figure 29:Our lenses refract light so that light rays of objects we look at end up in focus.[14]
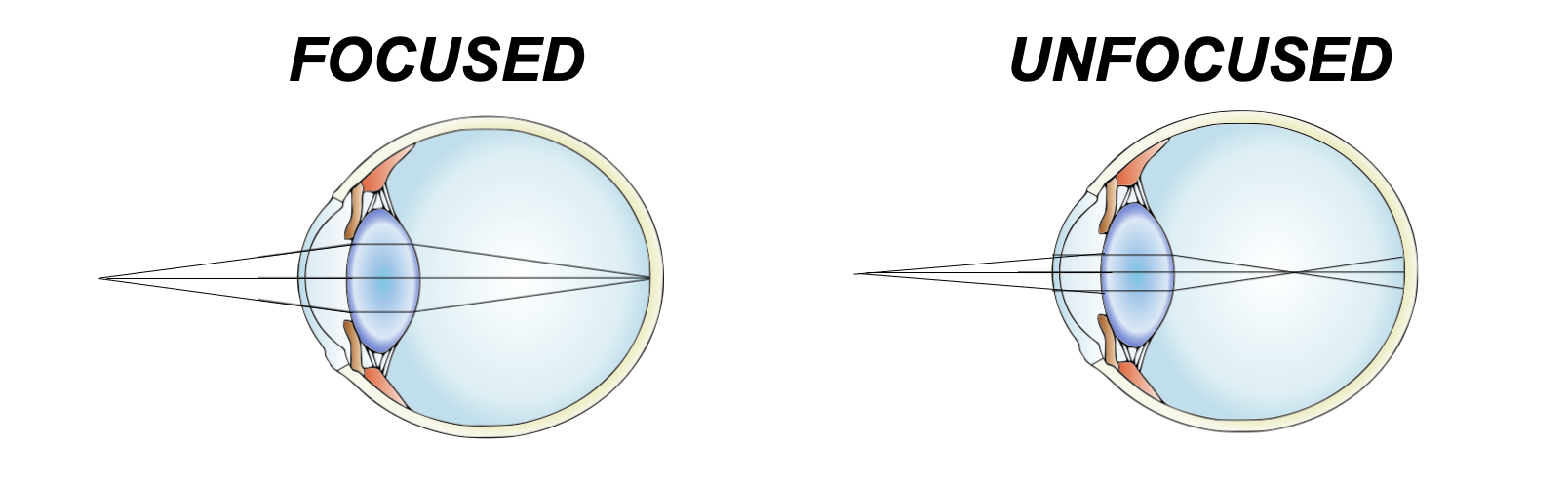
Figure 29:Our lenses refract light so that light rays of objects we look at end up in focus.[14]
PSYCHOLOGY¶
Sensation and perception is commonly taught by faculty in psychology departments. This is often, though not always, also the main home of perception researchers (many neuroscientists that study perception are housed inside Medical Schools). We thus will go with labeling this chapters as a summary of the psychology of perception (seeing, or vision, in the current case).
However, note, that some psychologists define psychology as the science of human behavior. This definition can still be applied to a large part of perceptual psychology since many researchers exclusively measure perception indirectly via behavioral report, such as button presses or verbal descriptions.
Yet, there is also an aspect of perception that gets lost in this framework - how perception presents itself (to us). And even when we exclusively consider perception-related behavior, this first-hand experience of ours with perception can become part of the equation.
For example, when we learn that some people cannot distinguish colors near red and green (color weakness, or more colloquially - and technically incorrect - color blindness) as well as others, students (and in fact, scientists) will inherently wonder what that is like. Accordingly, attempts are often made to alter color images so that normal observers can experience (via simulation) what a person with color weakness perceives. Likewise, there are attempts at expanding the color experience of people with color weakness to experience what being able to see more shades of hue might be like.
The same goes for learning people that cannot discriminate faces, objects, or who cannot see motion. Part of the process of understanding these phenomena is wondering about what remains, such as whether these people still see objects, faces, or motion like we do, but struggle to make sense of what they see. In other words, since we are ultimately studying perception, and not just its behavioral corollaries, we invariably use our own perception as an additional data point that seems challenging to eliminate from the equation without losing sight of the subject at hand.
Phenomenology¶
One way to account for this interesting issue is to acknowledge that what we mean by “psychology” in this, and similar sections, is not exclusive to behavioral output. Instead, we will also - often implicitly, and sometimes explicitly - leverage our own perceptual experience to interpret these behavioral findings. In fact, we have already done so at the very start of this textbook when we pondered a visual illusion. We will count your own perceptual experience as a valid data point.
Some may call this added data point as being derived from “introspection”. Technically, it seems a bit unclear whether any active process is taking place - let alone what is internal about it - when I look at something red and see red. Yet, it is fair to point out that using your own perception to derive knowledge about perception seems to deviate from using data that is derived from other people. The outcome of this process is sometimes referred to as phenomenology. Many people use this term in a variety of contexts and definitions, but for our purposes, adding this note about “phenomenology” only is meant to expand on a possibly too narrow definition of psychology to incorporate the science of perception.
Back to the topic at hand - what does all that mean for how we see?
Visual Field¶
The first thing one notices when pondering the nature of seeing is that one can quickly derive some simple facts about what we see. First among these is that we do not see all around us. We only see what it is in front of us. That is, the visual world that we encounter (including that of our dreams) is only half.

Figure 3:Visual fields (gray shade) of different animals shown along the horizontal plane (i.e., angle around the head that is visible to these animas).[15]

Figure 3:Visual fields (gray shade) of different animals shown along the horizontal plane (i.e., angle around the head that is visible to these animas).[15]
The reason that we cannot see what is behind our heads is simply due to the fact that both of our eyes face to the front, of course. Interestingly, this is not the rule among animals, let alone mammals. Many animals do not suffer from this limitation. In particular, animals that frequently face predators tend to feature eyes (usually on each side of the head) that allow for seeing almost all around them.
We call this fraction of the entire possible world that we could possibly see (if our eyes were to the side, like the eyes of horses), the visual field. For most humans (and other primates), the visual field roughly reaches 180 degrees around our body horizontally as well as roughly 180 degrees vertically.
You can test this yourself: Keep your eyes steady to the front (e.g., by fixating on an object straight ahead of you). Then, stiffen your arms, hands, and fingers so that they are all in line. Hold them right in front of you as if you are pointing with both arms and hands at what you are looking at. Now, move them apart laterally so that your left and right arms and hand slowly become parallel with your shoulders. Keep your eyes steady as you do so. You will probably be able to move your arms even further beyond the point of being parallel to your shoulders. But as you do so, and you keep looking straight ahead, your hands and arms will vanish from view. You can move your hands a bit back and forth, and you can easily see where the “borders” of your field of you are located. Here is a bonus: Keep your eyes at that point for a moment and close one eye and the other if you can. What do you see now?
This all is very basic and trivial, of course. But it allows us to move towards describing quite rigorously (and indeed mathematically when using degrees of angle) what we see. And this is just a starting point.
Now that we appreciate that what we see is extending 180 degrees horizontally and vertically in front of us, the next step is to think about what that is. And a somewhat trivial, yet surprising answer is: space.
Fronto-Parallel Plane¶
To keep things simple, let us think about two-dimensional space first. In other words, let us consider a plane. One might object that what we see is not just a flat, two-dimensional image. But that actually warrants a bit of consideration. As we will see, the 3D nature of our vision (i.e., the fact that we see depth) actually resembles a bit more of an inference in that is based on a small set of rules. However, more than that, we clearly can just see in 2D. That is, we can have perfectly normal, fine vision and fill our entire visual field with just a plane.

Figure 3:White noise. By moving close to your monitor, you can fill close your entire visual field with this two-dimensional image. At that point, all you see is movement within a plane that runs parallel to your eyes.[16]
Gestalt¶
Early psychological research on visual perception revealed something astounding: There is a class of visual illusions that we cannot escape falling for. Even once we understand that what we see is illusory, the illusion largely persists.
A large group of these visual illusions all seemingly do the same: they force us to see groupings of individual elements - we see a whole rather than just individual elements or parts.
Careful consideration reveals that we can identify a small set of rules that govern how we group these image elements (usually single lines, or dots) into groups. These rules have been named after the branch of psychology that studies these rules: Gestalt psychology. Many students have heard about this school of psychology using the phrase “the sum is greater than its parts”, though one could argue that the visual groupings we perceive are really just a sum. Gestalt psychology is also often taught as a branch of psychology that dominated research more than a hundred years ago. However, Gestalt psychology is more than just a fad. There are many Gestalt psychologists actively working today. Studying when and how we group visual elements is an ongoing, active research line with many practical implications, such graphical design (in particular iconographic logos for companies, or websites).
A brief list of well-identified Gestalt rules comprises:
Closure - our tendency to complete geometric shapes, even if some of their elements are interrupted (and only the image background is shown at that location). Rather than seeing an isolated set of lines, we tend to perceive a shape that is partially obstructed. This tendency to infer occlusion when we see incomplete visual objects is also called amodal completion. Arguably, this is a useful thing to do for our brains since it allows us to identify what might be partly hidden, such as a predator lurking behind dense brushes. Indeed, amodal completion can be demonstrated to be used by newborn chicks right after they hatch from their eggs, suggesting that, at least in these birds, the tendency of the brain to complete partial geometric shapes is inborn (innate).
Another such rule is symmetry. Whenever we see an abstract set of lines form a symmetric pattern, we tend to group it into a shape.
Common fate groups image elements whenever they move in unison.
Similarity groups image elements that look the same, such as red dots among black dots.
Good continuation is a Gestalt rule that explains how we see crossing patterns of lines to continue whenever they cross (rather than seeing them end at their junction).
Simplicity is the tendency to see the lowest amount of shapes whenever they are put in proximity. Rather than seeing three individual lines, we see triangles, for example.
There are many more Gestalt rules, but this list should give you an idea of how a small set of basic (possibly innate) rules that seem “hardwired” into our brains compels us to see shapes and simple objects rather than isolated parts whenever we open our eyes. Most of the time, these shapes and objects relate to distinctions that are behaviorally useful, such as distinguishing what might be in the foreground or background when objects are partially obstructed (recall that the image in our eyes is just a flat, two-dimensional “photograph” of the three-dimensional world). It is only when we create artificial situations, where we seem to apply these Gestalt rules stubbornly despite the fact that alternative interpretations of the resulting patterns and shapes are conceivable (thus creating an “illusion”), that we realize that they are seemingly always applied. Illusions, then, arise by misapplying heuristic rules that help us interpret the images in our eyes to (rare) situations where they fall short.
Multistability¶
An interesting situation arises whenever we create sensory stimulation that puts two or more alternative image interpretations (such as Gestalt rules) in conflict. That is, we can create (usually artificial) images that can be interpreted (give rise to) one set of shapes due to one Gestalt rule and a different grouping due to another Gestalt rule. In this case, your brain does something remarkable: you see both possible interpretations, but only one at a time. That is, perception (randomly) goes back and forth between these two (or more) possible image interpretations. The result is that your perception dynamically changes while the image in your eye is static and unchanging. These illusions are called bistable, when they perceptually alternate between two possible interpretations, or multistable when there are three or more ways of seeing the image over time.
Depth¶
Each eye collects the image formed by light rays on a flat, two-dimensional surface (the retina). As a result, our brains only receive information about the visual world in the form of a flat image, similar to a painting, or photograph. So, how come we see in 3D? How are we able to see what is close to us or further away?
This, too, happens by our brains applying a simple set of rules, similar to the Gestalt rules compel us to see patterns and shapes. And similar to the Gestalt rules, we can “trick” our brains to misapply these rules to force visual illusions.
Depth Cues¶
Let us discuss the rules that the brain applies to assume if an object is close to us or further away, one by one. In reality, these rules are often applied in combination.
Many of these rules have been discovered not by psychologists, but by artists. After all, in order to paint a three-dimensional scene onto two-dimensional canvas needs to “trick” our brain to see 3D depth where there is only a flat surface of paint. Interestingly, it took humanity hundreds of years to uncover the full set of rules that allows artists to create such “photorealistic” paintings. Many paintings that are hundreds of years old thus do not convincingly look three-dimensional.
Stereopsis¶
Most people are aware that one way that our brains turn the 2D images in our eyes into a 3D perceptual scene is by using binocular vision (i.e., both of our eyes). This is the reason why 3D movies need to be watched using specialized glasses. These glasses split (filter) the movie in two to show a different image to each eye, thus mimicking what happens in real life: Since our two eyes sit a bit apart in our skulls, the image in each eye is slightly different. You can convince yourself of that fast on stretching out an arm, and pointing a finger on an object in the distance. Then close one eye. Right after that, close the other eye while opening the eye you closed before (you can use your free hand to cover one eye a time). You will see that with one eye open your finger points right onto the targeted object, but when you change the eye, the finger seems to “jump” and point to the side of that object. The reason for this effect is that there are two slightly offset images falling into your eyes since the two eyes are offset laterally in your head.
Our brains can use that horizontal offset that occurs between objects in one eye with respect to the other to extract their distance to us. This horizontal offset is called disparity (or, more precisely binocular disparity). And the fact that we can use this disparity to see 3D depth is called stereopsis (a mix of the word “stereo”, indicating that there are two sources, and “opsis” for the visual image).
However, note how closing one eye only minimally changes what we see. If stereopsis were the main mechanisms by which we see 3D depth, closing one eye should make us see the world significantly more flat. This is not so. The conclusion is that the other depth rules that we discussed above are the main mechanism by which we see 3D depth. Indeed, up to one fourth of the human population perceives little difference when disparity is introduced to a movie. In other words, using “3D goggles” in, say an IMAX theater, changes very little to the visual perception of these people. To some people, there is no difference at all - a phenomenon called stereoblindness (perhaps better called “stereoweakness” since it occurs to varying degrees). The fact that so many of us rarely, or not at all, exploit the image difference between our eyes to see depth suggests that the depth rules discusses above are sufficient to successfully interpret the flat 2D images seen in just one eye to visually navigate the 3D world around us. It also explains why some people are not very impressed by watching a 3D movie with specialized goggles, and why this technology has not taken over the movie industry.
Color¶
Color can be the most confusing part of learning about vision. The reason for that is that color is arguably the most subjective part of our vision. We have already learned that visible light does not consist of different colors, but different wavelengths. The main difference is that we see a limited set of colors that can be grouped into larger sets, such as red, yellow, green, and blue. Orange, for example can be thought of as a shade of red, or a mix of red and yellow. Likewise, purple seems like a mix of red and blue (a reddish blue, or blueish red). In contrast, wavelengths simply just differ in frequency - there are no “special” frequencies, or “grouped” frequencies. There are, of course, mixtures of light wavelengths (frequencies), but some of the colors that we perceive as a mix, such as orange or purple occur when see light of a single frequency.
In the same vein, we understand that some animals can see parts of the light spectrum that is invisible to us. Bees and some birds, for example can see ultraviolet (UV) light that we are blind to. Do these animals see colors that we cannot see?
Another peculiar fact is that, if we look at the full spectrum of light, such as a rainbow (which arises when light is split into its frequency components by small rain drops acting as a prism), we cannot make out certain colors such as pink or brown. In other words, some of the colors we see are not just one wavelength of light. Some, but not all, combinations of light wavelengths give rise to entirely distinct colors. On the flip side, we can see yellow as part of the rainbow, demonstrating that there is a single wavelength that we tend to experience as yellow. But we can also see yellow when we use a red and a green light and mix their light rays. In other words, we also see yellow for a mix of two wavelengths, none of which corresponds to, or even overlaps with the wavelength of light that we (also) see as yellow.
Lastly, visual illusions teach us that we can see the same wavelengths of light as different colors, depending on context. A white piece of paper looks white to us, for example, even if we sit in a room that is only illuminated by a light source that emits orange rather than white light, such as a fireplace or an incandescent light bulb.
All the above can be readily explained by how we see color.
Recall that we have three different kinds of photoreceptors (cones) that we use for color vision. Each of these cones best responds to just one wavelength. This creates a simple mapping for some colors and our color vision:
When the L cones are maximally excited (using their preferred long wavelength) in isolation, we see red. In other words, long wavelength light tends to be perceived as red. L cones are thus also sometimes casually referred to as “red cones”.
When the M cones are maximally excited (using their preferred long wavelength) in isolation, we see green. In other words, medium wavelength light tends to be perceived as green. M cones are thus also sometimes casually referred to as “green cones”.
When the S cones are maximally excited (using their preferred long wavelength) in isolation, we see blue. In other words, short wavelength light tends to be perceived as blue. S cones are thus also sometimes casually referred to as “blue cones”.
In other words, most humans sense the light spectrum via three “peaks”, or measurement points. The rest is sensed as a mix of these three values (i.e., a mix of each of the three cones being excited to a varying degree each). Scientists call this trichromacy, which stands for the fact that there are three (tri) “primary” colors (chroma) that our eyes dedicate a single photoreceptor to.
Now, let us revisit yellow. There is a single wavelength of light that falls in-between the M and L cone, and thus excited both of them. This single wavelength we perceive as yellow. You can probably see now what happens when we excite both the M and L cones using green and red light: they also both get excited. As a result, we see yellow in either case. Our brains, only receiving what the eye tells it about the pattern (the relative) activation, or excitation, of cones simply cannot tell the difference. The resulting situation that there are different combinations of light waves that we all perceive as the same color is called a metamer. A metamer is one and the same color that we perceive for different light wave combinations.
Color Space¶
Another confusing observation that arises after appreciating what we just discussed (that we see color not by telling wavelengths apart by frequency, but how they differentially activate one or more of our three cone types) is why we can arrange color in a circle. After all, the spectrum of light results in a line that stretches from low to high frequency.
Scientists long were baffled by this fact. Why does blue (one side of the linear light spectrum) “wrap around” and meet red (the other end of the linear light spectrum) in a circle by purple acting as a “bridge” of sorts between them?
The main clue for this phenomenon is even more baffling: The reason that we can orient the colors we can see in a continuous round disk or circle is that we can mix some colors (e.g., using color lights or paints), but not others. In particular, we can mix red and yellow to create orange. We can also mix red and blue to create purple. Or we can mix blue and yellow to create green, and so on. We can even easily envision these color mixes. When someone says “a greenish blue”, most of us can see a sort of teal in our imagination.
However, there are some “forbidden” color mixes that we cannot even imagine. These are: a blueish yellow (or yellowish blue) and a greenish red (or reddish green)
No matter how hard we try, we cannot imagine that these colors could even exist. And when we attempt to mix these colors in practice, such as using paint, we indeed end up with colors that do not match those descriptions:
Mixing blue and yellow light results in white light (not a blueish yellow).
Mixing red and green light results in yellow light (not a greenish red).
When we mix paint, the result is even more disappointing:
Mixing blue and yellow paint results in brown.
Mixing red and green paint results in brown.
We will discuss in a moment why paint mixing differs from mixing light (the explanation is rather simple). For now, it is just important to note that there are two pairs of colors that cannot be mixed the other colors in that they do not result in a mix that readily reveal to us what they are made out of.
This interesting phenomenon is the basis of the notion of “unmixable” opponent colors (red vs. green, and blue vs. yellow). And it is the very fact that these colors can, in fact have to, be placed opposite to each other (since there is no clear mix that provides a gradual transition between these pairs) that we end up with the color circle: The color circle comes about by placing green opposite to red and blue opposite to yellow. Any other color then can be placed by transitioning between these four “poles”.
How can this be explained?
The answer lies in how our brains process the signals from the three cones: Red and green cone activation is processed uniquely by our brains. That is, rather than simply processing red and green cone activation as a mix, the brain unites red and green excitation into a new color (yellow). In the same vein, the brain treats blue cone activation uniquely if it co-occurs with red and green cone activation. As a result, blue and yellow are also to “opposing” colors.
The actual neuronal circuitry that causes this unique treatment of these four opposing colors is indeed based on an “opposing” mechanism, part of which has been identified to occur at the first stage of neuronal processing that occurs where the signals of the eye arrive in the brain (the lateral geniculate nucleus). We will return to this mechanism once we discuss this structure.
Lastly, why does mixing paint result in different colors than mixing light (such as when placing two differently colored filters on two separate flashlights and shining them onto the same spot)?
The answer is that paint absorbs light and only scatters the wavelengths that have not been absorbed. Red paint, for example, absorbs all wavelengths of light other than the long wavelengths that we perceive as red. When me mix more and more differently colored paints together, we thus end up with a paint mix that absorbs more and more wavelengths (resulting in brown, and eventually black - when all wavelengths get absorbed): Mixing red, green, and blue paint, for example will end up absorbing virtually all wavelengths since each of the wavelengths that one of these paints scatters when used in isolation is now absorbed by another pain in the mix.
This effect does not happen when we mix light itself, of course. In this case, the light that is scattered of the surface that we project on simply contains more and more different wavelengths, thus more and more approaching white light (which contains all wavelengths that we can see).
Color Anomalies¶
Some people are born with one or more dysfunctional cone type. This is known colloquially as color blindness, though it comes at varying degrees and thus would more accurately be called “color weakness”. Of note, people with color weakness still see (many) colors. In fact, it can be challenging to detect color weakness since it only affects a small set of color mixes.
Since there are three different types of cones, there also are three different kinds of color weakness (one for each cone). There also is a rare color weakness where it is the rods rather than one of the cone types that does not function normally.
The most common case of color weakness rests on a dysfunctional, or lacking, M cone, and is sometimes referred to as red-green blindness since a lacking M cone (while retaining a functional L cone) will result in an ability to see all the gradations of colors that fall in-between red and green. The gene that is responsible for this form of color weakness is located on the X chromosome. Someone with two chromosomes (XX) has a built-in redundancy - if one of the X chromosomes contains a damaged gene for M cones, the other X chromosome might contain a functional copy. People with XY chromosomes are thus more likely to be born color weak.
Color weakness affects ~5% of the population and thus should be kept in mind when using color for communication. Rather than just differentiating visual information by color, it is helpful to also use different levels of brightness so that anyone can see as separate what is meant to be shown as separate.
Interestingly, there is also some evidence that some people might see more colors than the rest of us. Having to X chromosomes can lead to having two versions of M cones, each best responding to a different medium wavelength. The result is tetrachromatic vision (tetra stands for four). These individuals are exceedingly rare, and there is heavy debate in the literature whether these people can indeed see more colors than other humans, with evidence leaning in both directions (partly because there have not been that many studies).
Motion¶
Akinetopsia¶
Objects¶
Agnosias¶
Faces¶
Prosopagnosia¶
Pareidolia¶
ANATOMY¶
Before we can discuss how we sense (and then perceive) light, we first need to review the basic makeup of the part of our body that does the job: our eyes.
Our eyes can be thought of as large fluid-filled spheres, almost like balloons. These spheres can be further divided into the following parts:
The sclera is a skin-like tissue that envelops much of our eyes. The sclera is the white part that we see when we look at someone’s eyes.
The iris is the colored annulus that we see surrounding the pupil. The pupil is the black spot at the center of someone’s eye when they look directly at us. The pupil is, in fact, just an opening. What we really look at when we see a pupil is the back of that person’s eye.
In other words, the iris is donut-shaped, and the hole at the center of that donut is what we call the pupil. Does this mean that we have an open hole in the center of our eyes? If so, why does the fluid inside not spill out? The answer is that the lens is a transparent cover that sits behind that hole and seals it shut. There is also a second transparent layer of tissue at the very front of the eye called the cornea. This means that when see a black pupil, what we actually look at is the following: a transparent cornea, transparent fluid, a transparent lens, and ultimately - the retina at the back of the eye which absorbs so much light that it is completely black.
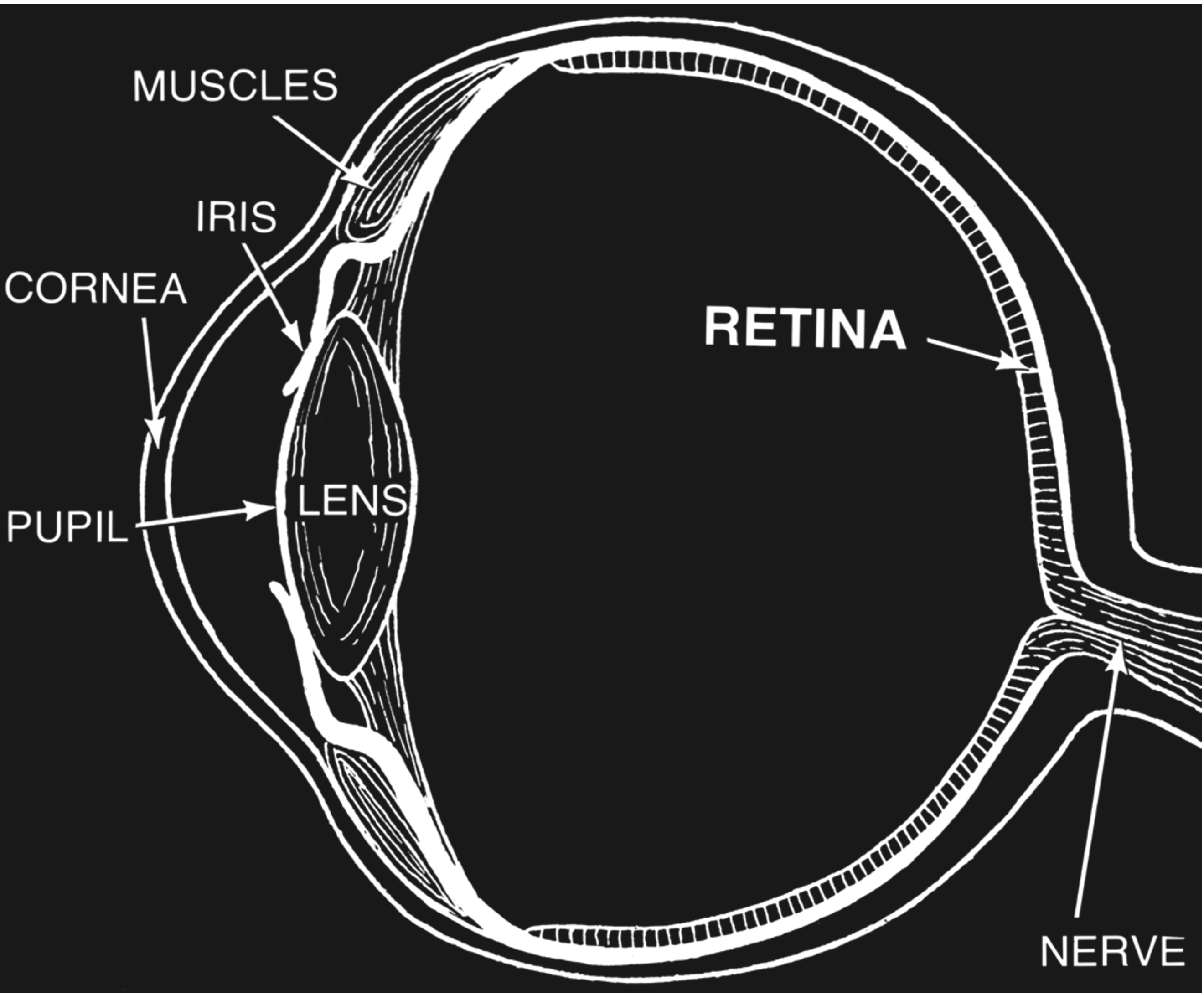
Figure 34:Anatomy of the eye.[17]
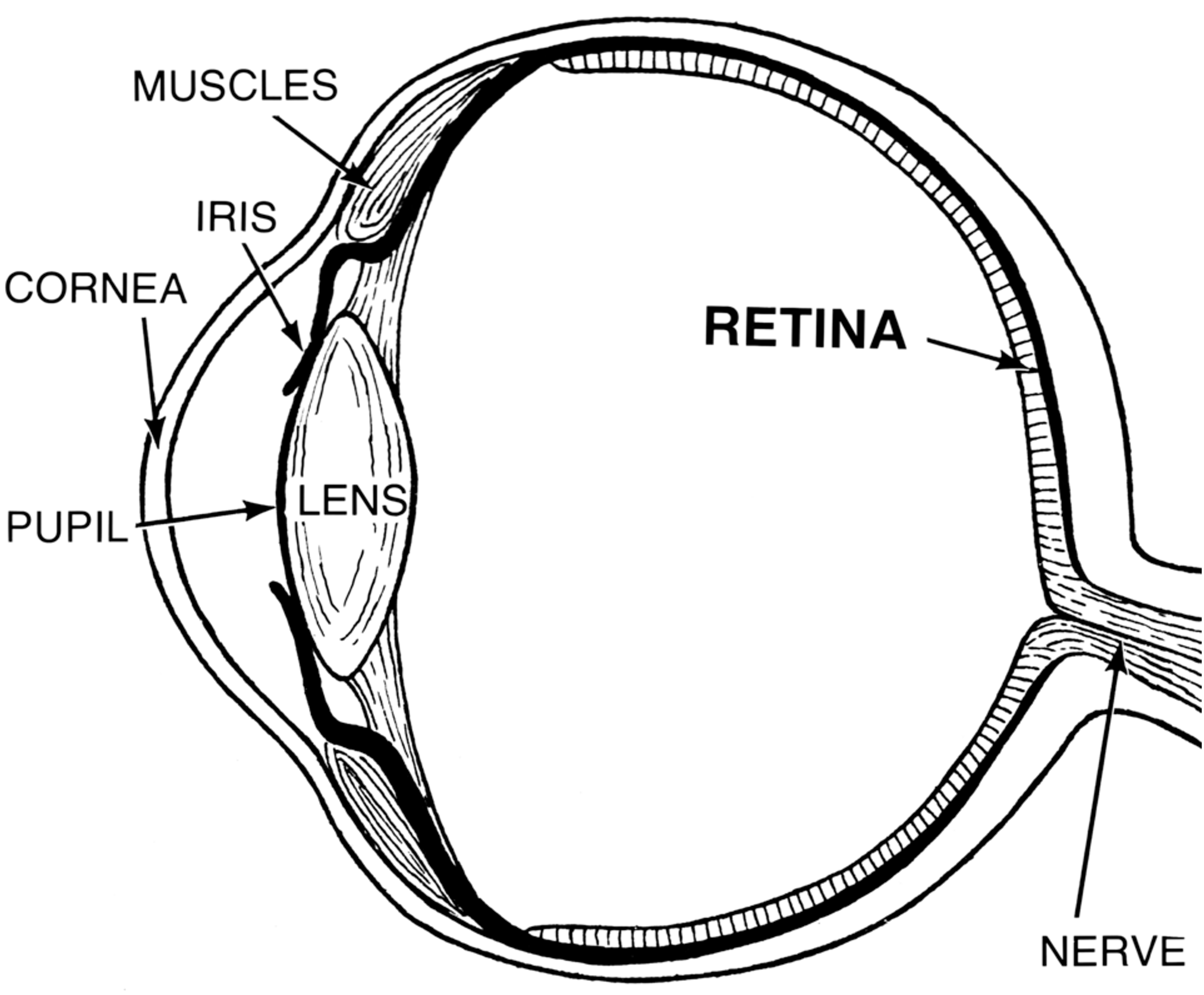
Figure 34:Anatomy of the eye.[17]
The lens is held in place by muscles. When these muscles constrict, the lens is pulled into an elongated shape. The change of that shape changes its refraction in a way that we can focus on objects at varying distances. This process is called accommodation.

Figure 36:Illustration of the process of Accommodation: The lens of our eyes gets deformed when we focus on objects that are near or far from us, resulting in a change of diffraction that ensures that the light projection on the retina is in focus.[18]
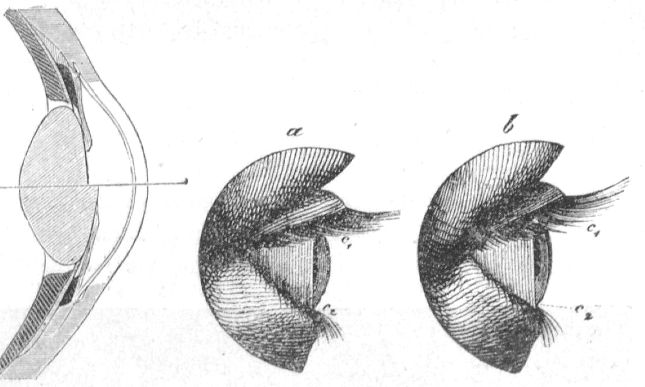
Figure 36:Illustration of the process of Accommodation: The lens of our eyes gets deformed when we focus on objects that are near or far from us, resulting in a change of diffraction that ensures that the light projection on the retina is in focus.[18]
NEUROSCIENCE¶
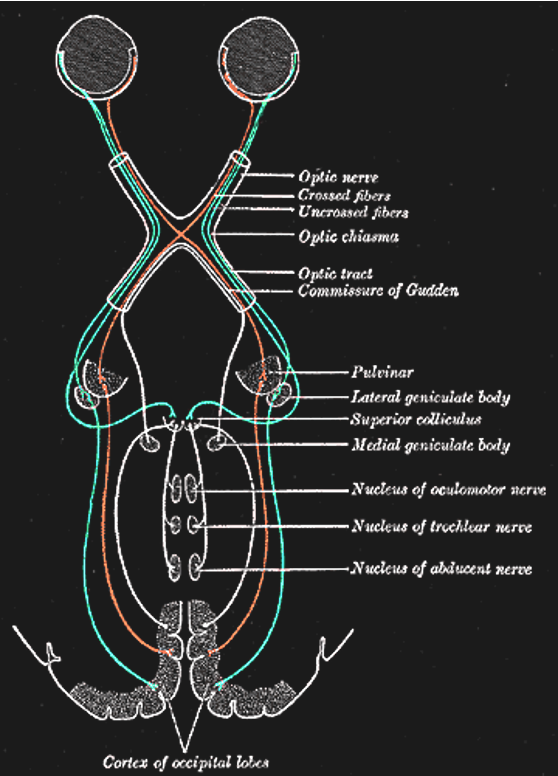
Figure 3:The primary visual pathway, colored coded by visual field (not by eye). Neurons (retinal ganglion cells, or RGC) from both eyes first meet at the x-shaped optic chiasm. Half of the fibers cross so that the fibers from each eye that correspond to the same visual hemifield are bundled. These fibers then terminate at the dorsal lateral geniculate nucleus, or LGN, of the thalamus. Most LGN neurons then project to the back of the cerebral cortex and arrive at the primary visual cortex, or V1.[19]
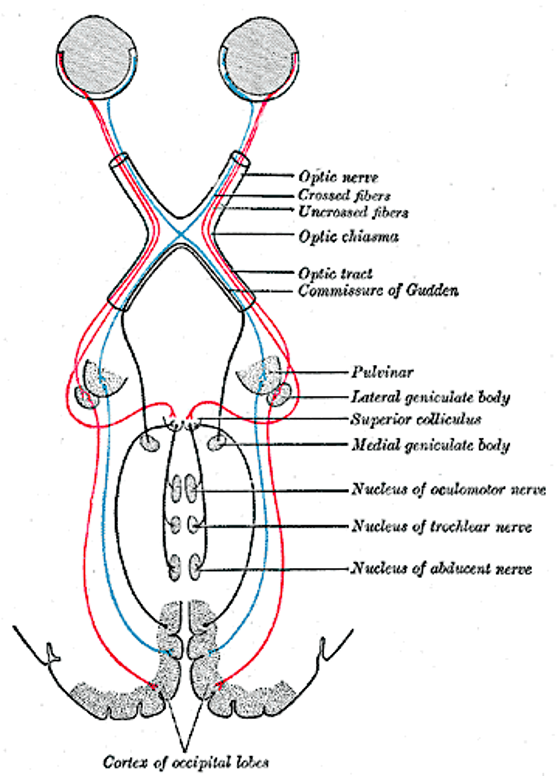
Figure 3:The primary visual pathway, colored coded by visual field (not by eye). Neurons (retinal ganglion cells, or RGC) from both eyes first meet at the x-shaped optic chiasm. Half of the fibers cross so that the fibers from each eye that correspond to the same visual hemifield are bundled. These fibers then terminate at the dorsal lateral geniculate nucleus, or LGN, of the thalamus. Most LGN neurons then project to the back of the cerebral cortex and arrive at the primary visual cortex, or V1.[19]
Retina¶
We already surveyed the anatomy of the eye as a whole and established that the key steps for vision is the bundling of light by controlling the shape of the lens in order to achieve refractive focus as well as controlling the size of the pupil’s size (opening) to adapt to varying amounts of light. The overall purpose is to ensure an optimal optic image on the back of the eye - the retina.
The retina is a part of the brain and consists of several types of electrically excitable nerve cells (neurons) that are organized in several layers.
At the very back of the retina (the farthest away from the incoming light) are the photoreceptors that absorb the light that enters the eye and transform it into action potentials. There are two major types, named after their shapes: the rods and the cones.
Rods are only functional during (very) low light conditions, such as a dark room in the middle of the night. When we use our cones, we can only see different levels of brightness - all colored objects look (shades of) gray. This type of monochromatic vision is called scotopic vision.
Most of the time we use our retinal cones to see (called phototopic vision, which leads to color perception). There are three types of cones that respond best to different wavelengths of light:
L cones respond best to the long wavelengths of light that we usually perceive as red.
M cones respond best to the medium wavelengths of light that we usually perceive as green.
S cones respond best to the short wavelengths of light that we usually perceive as blue.
Other wavelengths cause a mix of these cones to become active, resulting in other perceptual hues, such as yellow.
The photoreceptors contain molecules that change their shape when they get hit by a photon, and it is this change in shape that ultimately causes these neurons to get electrically excited. This process is called photoreception.
Interestingly, our photoreceptors are never fully inactive. Even in complete darkness, they are somewhat spontaneously active. As a result, we cannot actually see “complete” darkness. The spontaneous activity of our photoreceptors causes us to perceive a slight amount of grayness (called “Eigengrau”, German for “self-gray”) even when there is no light at all entering our eyes.
The photoreceptors synaptically transmit their excitation to other neurons in the retina. These neurons can be divided into two types. The bipolar cells are the primary recipients of the signals of the photoreceptors that indicate rods or cones detecting photons. Bipolar cells align with photoreceptors in their shape, virtually forming a “vertical” line with the rods and cones. Bipolar cells either receive signals from rods or from cones, but never both. In other words, the bipolar cells keep the signals from rods and cones separate in that some bipolar cells are exclusive to rods and others to cones.
The other type of neuron that photoreceptors transmit their signals to via their synapses are called horizontal cells. These neurons stretch out “horizontally” (orthogonal or perpendicular) with respect to the photoreceptors and bipolar cells. Horizontal cells connect between both photoreceptors and bipolar cells, thus laterally “spreading” the activation, or allowing for signals between neighboring photoreceptors and bipolar cells to interact (so-called lateral interactions).
The bipolar cells in turn transmit their signals to retinal ganglion cells, or RGCs. In other words, light activation from photoreceptors follows a chain:
rods or cones activate -> bipolar cells activate -> ganglion cells activate
This chain of activation is called the vertical pathway. RGCs are the final step of retinal activation. Their axons exit the eyeball and project to the rest of the brain (primarily the lateral geniculate nucleus of the thalamus, which we will discuss next).
There is another type of neurons in the retina called the amacrine cells. These neurons mirror the horizontal cells in that they stretch out horizontally between bipolar cells and retinal ganglion cells, and they connect to both. Similar to the horizontal cells, this allows for signal interactions between neighboring bipolar cells and retinal ganglion cells.
The horizontal cells and amacrine cells, together, are sometimes referred to as the horizontal pathway. Note, however, that they are two separate layers that do not directly connect to each other. Horizontal cells only connect between photoreceptors and bipolar cells. And amacrine cells only connect to bipolar cells and retinal ganglion cells (RGCs).
What is the function of this retinal circuitry? Why do the photoreceptors not just send their signals to the brain directly?
One clue is that RGCs respond to light in a more sophisticated way, which is believed to arise from the lateral interactions. Specifically, RGC’s tend to respond to more than just one rod or just one cone, but a smal set of neighboring photoreceptors. The result is what we call a receptive field - a small area of the retina receiving light. Due to the optics of the eye, each receptive field corresponds to a small spot of your visual field.
More than that, RGC receptive fields are not just small sensitive to small spots of light. Instead, they contain two parts: a central spot (the center) and a surrounding annulus, or ring (the surround). The center and the surround of these receptive fields tend to have exact opposite preferences for light:
So called on-center RGCs get most active (they “turn on”) when light hits the center of their receptive field. However, their peak activity is reached when the light only falls into their center, and there is no light in their surround.
A second set of RGCs (so-called off-center RGCs) does the opposite: They are most excited when light falls into their surround while there is no light inside their center.
The result of RGCs responding in this way is interesting: The output of the retina is most pronounced when light is distributed locally rather than wide areas of the area receiving the same amount of light or no light at all. That is, the signals that the retina sends the rest of the brain emphasize parts of the optic image where light areas meet dark areas and thus create local contrast.
One way to appreciate this phenomenon is that the brain is most interested in differences. All light or all dark is less exciting than transition between light and dark. Indeed, we will see that this general notion pertains too much of neuronal responses in our brains more generally. Put glibly, our brains are easily “bored” whenever there is “more of the same”. What excites our brain most is when or where something changes.
There is a direct consequence of this that can be dangerous: Under some circumstances we can perceive this over-emphasis of RGCs. The resulting visual illusion is called Mach Bands (after the discoverer Ernst Mach). These are bands are illusory stripes that occur along transitions between dark and bright parts of images. In daily live, this illusion frequently occurs when looking at X-Ray images and cause radiologists or dentists to misinterpret and thus misdiagnose these images.
The axons of the RGCs bundle up and exit the eye at the optic disk, which is named after its white round appearance when looking at someone’s retina with a medical device called a fundus scope (also called an ophthalmoscope) or a fundus camera. There are no photoreceptors on top of the optic disk, thus causing us to have blind spot in each eye.
We cannot see our blind spots since the blind spot in one eye corresponds to an area of the retina that does have photoreceptors in the other eye. So, one eye covers the blind spot of the other eye. Even with just one eye open, we cannot see the blind spot in that eye thanks to our brain filling-in that spot by interpolating the image that surrounds it. Any visual objects that fall only inside the blind spot get replaced by seeing whatever is nearby and thereby disappear from view (without leaving a dark or black area).
Optic Nerve¶
The bundle of RGC axons that laves the eye is called the optic nerve. Each eye’s optic nerve contains about one million axons. Each axon transmit information about a single receptive field, and thus only a small spot of your entire visual field. Damage to some of these axons thus laves to a small localized loss of sight, or additional blind spots, called so-called scotomas (singular: scotoma). Humans are not able to recover form such damage. Such localized blindness is permanent.
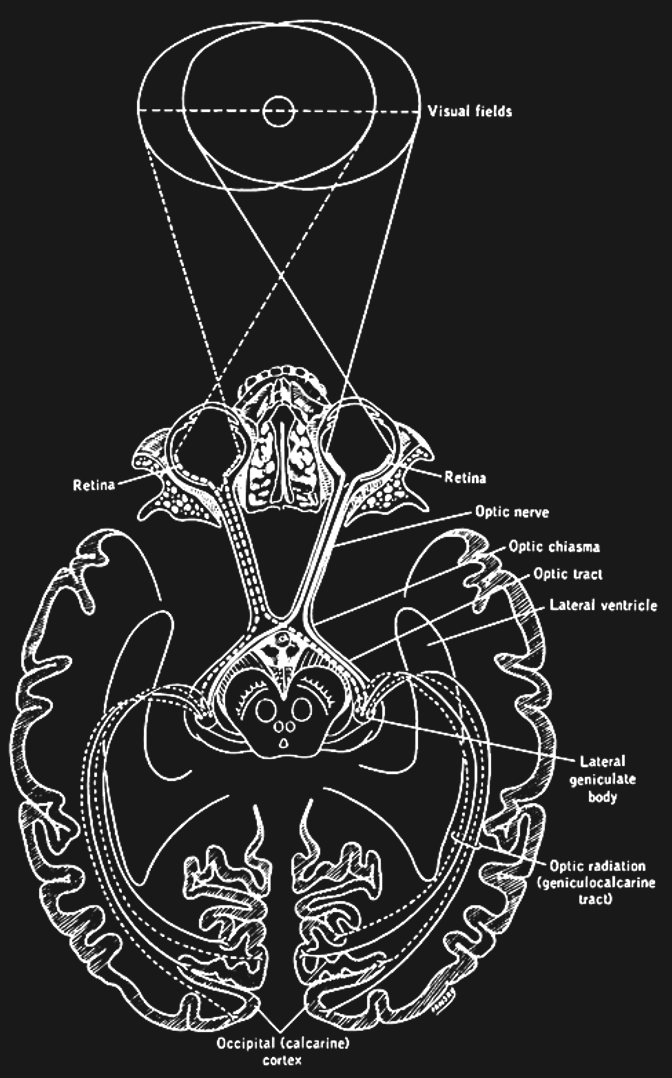
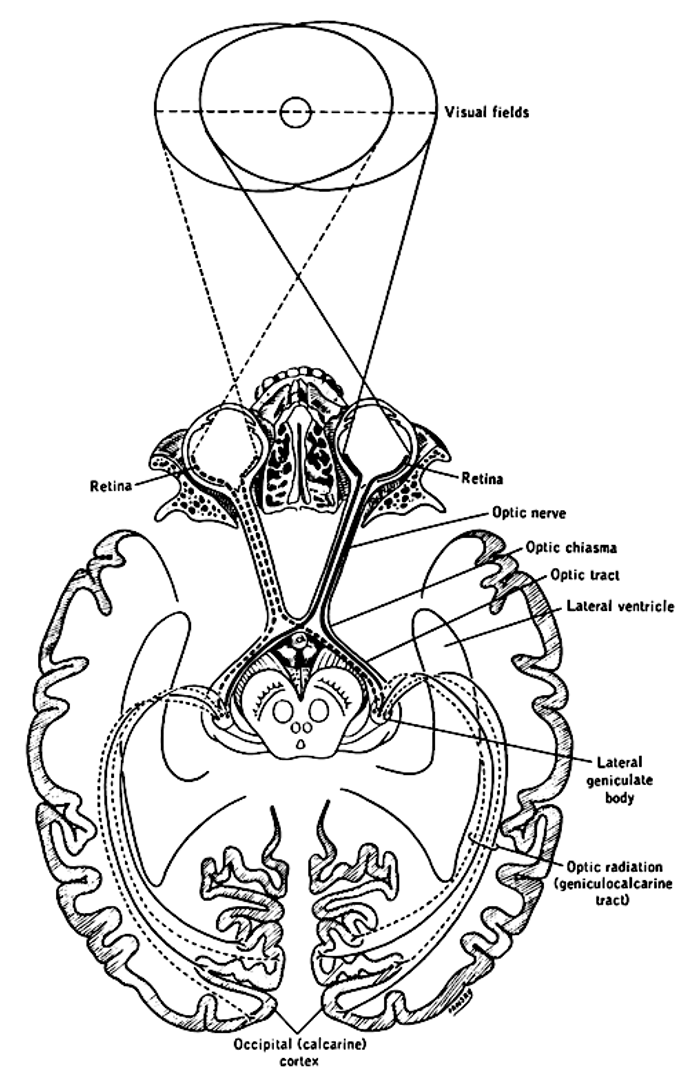
Optic Chiasm¶
The two optic nerves meet - and cross - a short distance behind the eyes in an X-shaped structure called the optic chiasm. The axons do not end at this location, they merely divide into two separate bundles called the optic tract (an extension of the optic nerve).
Importantly, the axons do not just cross so that the left eye projects to the right half of the brain or vice versa. Instead, they split the RGCs from each eye in half so that the left retina of both eyes (corresponding to what is located to the right of your nose due to the flipping of the image by the lens) projects to the left part of the brain. Likewise, the right halves of your retinas send their signals (corresponding to what you see to the left of your nose) to the right part of your brain.
The result of this peculiar splitting of retinal information by the optic chiasm is that the left half of your brain only “sees” what is to the right of your nose and the right half of your brain only “sees” what is to the left of your nose.
The two halves (hemispheres) of your brain are heavily interconnected, thus sharing the information between them. But in some patients (split brain patients), the two hemispheres are largely separated. These patients can only verbally describe what they see to their right since only the left hemisphere contains an area for language production. Yet, they can draw what is shown to their right using their left hand, which is controlled by their right hemisphere.
A striking finding form studying these split brain patients is that they cannot verbally explain why their left hand can draw something, even though they seem normal in all other mental function. After all, the speaking part of their brains did not see what the right half saw. The result is spectacular - it seems like these patients’ brains give rise to independent conscious minds that do not know about each other’s existence. One of these minds we can verbally communicate with, while the other one remains mute. Indeed, these patients sometimes report that their hands sometimes are in conflict such as picking out differently clothes in the morning - a phenomenon called alien hand syndrome.
There is a lot of debate among researchers how to interpret this finding. It is appealing to speculate that half of our brain might be sufficient to support a conscious mind of normal intelligence, thus allowing to be split in two. However, not all scientists share that view, and point out that even in split brain patients one can still find a small amount of residual connections between the hemispheres. The split brain phenomenon thus remains an intriguing enigma. In our context, it is important to note that what gives rise to this phenomenon finds a source in the optic chiasm splitting our visual fields in half.
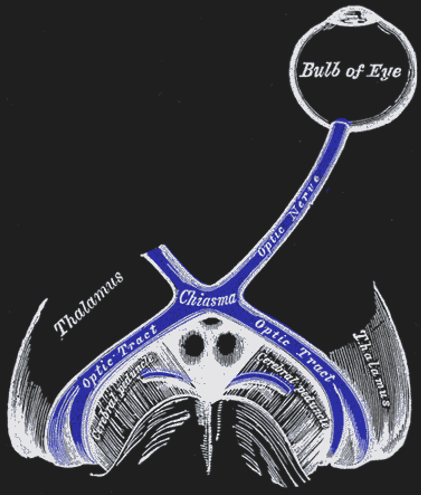
Figure 42:The optic nerves of both eyes meet at an x-formed structure called the optic chiasm.[21]
Figure 42:The optic nerves of both eyes meet at an x-formed structure called the optic chiasm.[21]
Lateral Geniculate Nucleus (LGN)¶
The axons from the optic tract terminate in the middle of our brains in a structure called the dorsal lateral geniculate nucleus of the thalamus, or LGN (sometimes abbreviated to dLGN) for short. The LGN has been well studied. It consists of several layers of neurons that receive either inputs from one eye or the other. There are six main LGN layers in total, and they roughly alternate in receiving inputs from one eye or the other (either from the eye of the same - or ipsilateral - eye, or from the other - or contralateral eye). The exact sequence is:
contra - ipsi - ipsi - contra - ipsi - contra
There are three types of layers in the LGN, each featuring a different type of neuron:
The magnocellular layers receive inputs from large retinal cells (with large receptive fields) called parasol RGC (or M cells). These neurons are most sensitive to rapid change such as flicker or motion, but poorly signal details (due to their large receptive fields).
The parvocellular layers of the lGN receive inputs from small retinal midget RGC (or P cells). These neurons have small receptive fields and thus are best for details and high acuity.
In-between the M and P layers of the LGN are koniocellular layers that receive inputs from bistratified RGCs. Their function is a bit less understood, but they are important for short wavelength (blue light) vision.
The receptive fields of LGN neurons largely resemble those of RGCs. The LGN therefore is often called a relay and thought to mostly just pass on the information of the retina to the rest of the brain. One function of the LGN seems to be that it can “shut off” this stream of information and stop relaying the retinal signals when we enter sleep.
Optic Radiation¶
Axons of LGN neurons “fan out” rather than forming another tightly bundled nerve. They run towards the very back of your brain, where they terminate and synapse (providing input to) your primary visual cortex.
Primary Visual Cortex (V1)¶
The primary visual cortex is also referred to as V1, striate cortex, or area 17. All steps of neuronal processing (by the retina and the LGN) we have discussed so far leads up to V1 receiving the bulk of their signals. V1 is part of the cerebral cortex, which is the main part of the brain that we currently believe supports conscious vision (in concert with the rest of the brain). There are many more parts of the cerebral cortex involved in vision, and we will discuss those next, but all of these areas mostly receive information about retinal signals from V1. In other words, V1 is the main “gatekeeper” and a “bottleneck” of sorts for our cerebral cortex to produce perception. Accordingly, damage to V1 results in loss of conscious visual perception (cortical blindness) - though some unconscious visual function remains.
V1 has been studied extensively by neuroscientists, culminating in a (1981) Nobel Prize. As a result, we know a lot about V1. However, whether V1 directly supports conscious perception is still debated. Some scientists argue that it merely provides the rest of cortex with the information from the eyes. Indeed, patients that lost V1 report that they still have visual experiences when they dream at night.
Secondary Visual Cortex (V2)¶
V2 neighbors V1, and receives most of its outputs. It thus tends to be thought of as a second “step”, or “stage” of visual processing by the brain.
V2 is anatomically quite distinct from V1, and much is known about its neuronal “architecture”. However, it nonetheless resembles V1 in most major ways: V2 has six layers of neurons. V2 has cortical columns. V2 features a retinotopic map and cortical magnification. V2 neurons respond similar to V1 neurons in that they respond to small linear receptive fields (though V2 neurons tend to respond slightly later than V1 neurons to visual stimulation; and V2 receptive fields are slightly more expansive - larger - than their V1 counterparts). So, is there something unique about V2?
The answer is yes. And what has been found is interesting:
V2 neurons differ from V1 neurons in that they can respond according to Gestalt rules. In particular, V2 neurons respond differently to one and the same bright-dark edge inside their receptive fields, depending on context. This response property has been termed border ownership since it seems to provide the basis for which edges we perceive to be part of (“owned by”) a shape, or Gestalt grouping.
V2 neurons with border-ownership respond to the parts of incomplete shapes (the gaps in shapes) that we perceive as “closed” (thanks to the Gestalt rule of closure) as if there were no gap. This V2 property could explain why we see these shapes as a whole despite there being a gap. This is remarkable. So far, we have only encountered neuronal responses to visual stimuli that reflect the physical stimulation rather than our perception. Neurons in the retina, the LGN, and in V1 seem to largely respond to the exact light patterns in our eyes - even when our perception deviates (i.e., when we see completed shapes despite there being gaps). These V2 neurons were some of the first neurons found by scientists whose responses more closely reflect what we see (a completion rather than a gap).
There is ongoing debate whether similar neurons in the LGN and V1 that respond according to our perception rather than physical stimulation (whenever the two deviate, such as during illusions). Indeed, the evidence is increasing that is the case for some V1 (and even LGN) neurons under some circumstances. However, we seem to find a larger proportion, or fraction, of V2 neurons whose responses more readily deviate from the image in our eyes and instead reflect our experience. An interesting question, then, is whether this proportion increases as we examine the ensuing steps of visual processing in areas V3, V4, and so on.
EYE MOVEMENTS¶
Extraocular muscles¶
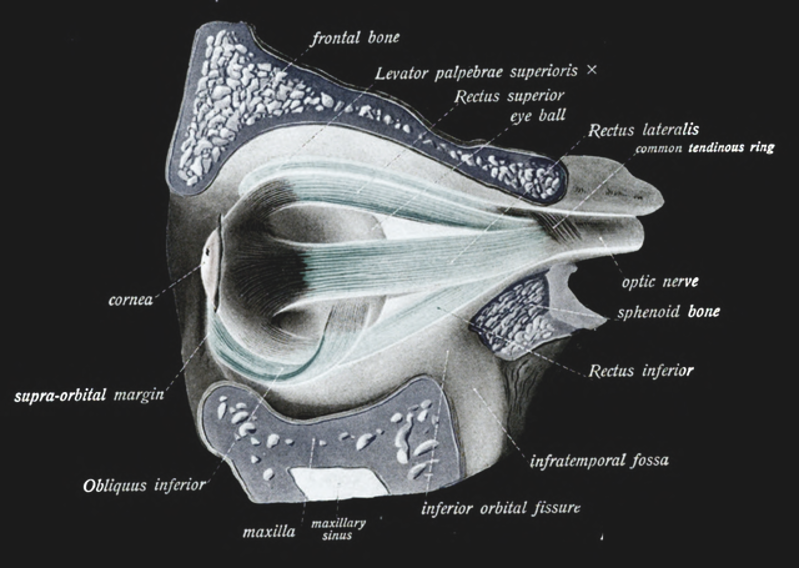
Figure 44:Extraocular muscles.[22]
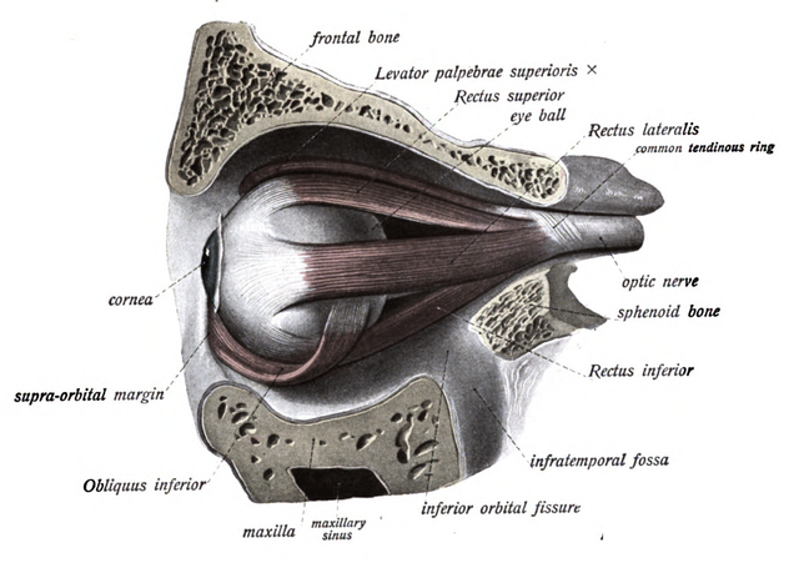
Figure 44:Extraocular muscles.[22]
- Maier, A., Cox, M. A., Westerberg, J. A., & Dougherty, K. (2022). Binocular Integration in the Primate Primary Visual Cortex. Annual Review of Vision Science, 8(1), 345–360. 10.1146/annurev-vision-100720-112922